
Po paru pierwszych wpisach dotyczących ogólnej charakterystyki wyników końcowych oraz rozkładu bramek, w tym wpisie przedstawię koncepcję wykorzystania regresji logistycznej do przewidywania wyniku końcowego meczu piłkarskiego. Jak by to górnolotnie nie zabrzmiało, spróbujemy stworzyć model, który pozwoli określić, z pewną dokładnością, czy dany mecz wygra drużyna gospodarzy czy też nie.
Do stworzenia takiej „maszynki” wykorzystana zostanie regresja logistyczna. Nie chciałbym przy tym zanudzić teorią oraz zaawansowaną matematyką dotyczącą tego typu algorytmu, dlatego zainteresowanych odsyłam do przykładowej strony w języku polskim oraz angielskim wyjaśniających w uproszczeniu ten algorytm. Możliwe, że innym razem bardziej skupie się na przedstawieniu szczegółów dotyczących działania RL, jednak tutaj chciałbym przedstawić ogólna koncepcje i możliwości.
Poniżej przedstawię dane, które wykorzystałem, zmienne, które wziąłem pod uwagę, proces tworzenia modelu, a na końcu zbadamy stworzony model pod względem jakości oraz zasymilujemy wyniki najbliższej kolejki w La Lidze (4 kolejka Ligi Hiszpańskiej sezonu 2018/2019).
Zbiór danych oraz kod, który został stworzony na potrzeby tej analizy możecie podejrzeć na moim repozytorium github. Warto podkreślić tu na początku, że kod służący do stworzenia modelów regresji logistycznej został stworzony w R.
Na ten moment warto wiedzieć, że regresja logistyczna ma zastosowanie w przypadku binarnej zmiennej celu, czyli tej, która modelujemy, a w naszym przypadku jest to zmienna „Końcowy wynik spotkania” (FTR). Pozwala oszacować wartość prawdopodobieństwa, z jakim dana obserwacja przynależy do określonej kategorii (grupy) zmiennej objaśnianej. Czy kolokwialnie mówiąc, jak prawdopodobny jest przewidywany wynik końcowy na podstawie stworzonego modelu. Pojawia się tu pewna nieścisłość, skoro regresji logistyczna ma zastosowanie głównie w przypadku dwóch kategorii, a przecież w naszym przypadku istnieją trzy różne scenariusze zakończenia spotkania, jak więc mamy dostosować nasze zadanie do podanego algorytmu ? Wystarczy spojrzeć na ilości historycznych wyników końcowych. Jak też zostało przedstawione już to w Przewaga własnego boiska stosunek zwycięstwa gospodarzy, zwycięstwa gości i remisu przedstawia się w przybliżeniu 2/1/1. Skłania więc to do „sklejenia” wszystkich obserwacji w których padł wynik zwycięski dla gości z tymi zremisowanymi spotkaniami. W takim przypadku stosunek dwóch kategorii wynosić będzie 50/50. A w konsekwencji wykorzystamy nasze dwie oczekiwane kategorię.
W przykładzie poniżej wykorzystane zostaną dane z ligi hiszpańskiej pochodzące z ostatnich sezonów od 2010/2011. W tym też przepadku rozkład zmiennej celu, którą w naszym przypadku jest wynik końcowy, przyjmującą dwie kategorie:
- zwycięstwo gospodarzy (1),
- zwycięstwo gościu lub remis (0),
przedstawia się następująco:

1479 meczów zakończonych zwycięstwem gospodarzy co daje 48,2% wszystkich analizowanych spotkań.
Analiza danych
Dane wykorzystane do analizy, jak zwykle, pochodzą ze strony http://www.football-data.co.uk/data.php . W tym jednak przypadku zostały one znacznie bardziej zmodyfikowane, tak by mogły być wykorzystane do wspomnianej analizy regresji liniowej. Na zrzucie ekranu poniżej widnieją tylko te zmienne, które nie są mocno skorelowane między sobą. Takie działanie miałoby negatywny wpływ na wyniki. Algorytm „faworyzowałby” zmienną , która jest wysoko skorelowana ze zmienna celu, a tym samym pomijałby wpływ każdej z pozostałych zmiennych, a tego byśmy nie chcieli.
Finalnie zbiór danych złożony był z następujących typów zmiennych:

Z otrzymanego wyniku można odczytać rodzaj danej zmiennej, czy jest ona zmienną typu ciągłego lub czy jest to zmienna kategoryczna. Trzynaście pierwszych zmiennych to zmienne typu factor, co oznacza, że są to zmienne kategoryzujące, a mówiąc bardziej szczegółowo, w analizowanym przypadku przyjmują wszystkie one po dwie kategorie (0 lub 1). Należy pamiętać, że zmienna FTR jest zmienną objaśniania, przyjmującą wartość 1 w przypadku wygranej gospodarzy, natomiast 0 w wypadku przeciwnym. Pozostałe zmienne kategoryzujące również mają po dwie kategorie – z tym, że są to zmienne objaśniające. Typ „num” oznacza, że zmienna przejmuje wartości liczb rzeczywistych. „Int” natomiast to liczby całkowite.
Skrócone objaśnienie:
- FTR – zmienna celu, wynik końcowy, przyjmująca dwie kategorie 1 w przypadku zwycięstwa gospodarzy, 0 w przeciwnym,
- HTWinStreak3 , HTWinStreak5, ATWinStreak3, ATWinStreak5 – zmienna przyjmująca wartości „1” w przypadku serii zwycięstw gospodarza (HT) lub drużyny gości (AT) o takiej długości jaka widnieje na końcu nazwy danej zmiennej,
- HTLossStreak3, HTLossStreak5, ATLossStreak3, ATLossStreak5 – analogicznie do poprzedniej, zmienna przejmująca wartości „1” w przypadku serii porażek gospodarzy lub gości o takiej długości jaka widnieje na końcu nazwy danej zmiennej,
- HM1 – wynik ostatniego spotkania gospodarzy, wygrana w przypadku wartości „1”, remis lub porażka, gdy 0.
- HM2 – analogicznie do HM1, z tymże wynik przed ostatniego meczu gospodarzy.
- AM1 oraz AM2 , analogicznie do dwóch poprzednich, tylko odnoszące się do drużyny gości.
- WHH – kurs bukmacherski na zwycięstwo drużyny gospodarzy w zakładach Willam Hill
- WHA – kurs bukmacherski na zwycięstwo drużyny gości
- WHD- kurs bukmacherski na remis w danym spotkaniu,
- HTGD, ATGD – różnica między bramkami strzelonymi a straconymi przed drużynę gospodarzy (H) oraz drużynę gości (A) na przestrzeni danego sezonu,
- DiffFormPts – różnica zdobytych punktów w trzech ostatnich spotkaniach
- DiffLP – różnica w pozycja w tabeli z poprzedniego sezonu,
- H2H_Diff- różnica zdobytych punktów w trzech ostatnich meczach bezpośrednich między danymi drużynami.
- Maret_Diff – róznica w rynkowej wycenie między drużyną gospodarzy a gości liczona w MLN EUR.
- Age_Diff – różnica w średniej wieku drużyny gospodarzy i gości.
Kilka ostatnich obserwacji ze zbioru danych przedstawia się następująco :

Budowa modelu
Po obrobieniu zmiennych i wybraniu odpowiednich zmiennych dokonany został podział zbioru danych na zbiór treningowy oraz testowy. W dużym uproszczeniu, na zbiorze treningowym zostanie zbudowany model, natomiast do celów jego weryfikacji zostanie wykorzystany zbiór testowy. Na tym drugim też, będziemy w stanie określić jak dobrze został dopasowany model do danych, czyli inaczej mówiąc jak dobrze sprawdza się stworzony model.
Po podziale zbioru, przystąpiłem do budowy dwóch modelu regresji logistycznej:
- model uwzględniający wszystkie zmienne zawarte w zbiorze danych,
- model uwzględniający tylko te zmienne , które w tym przypadku będą istotne statystycznie.
Pierwszy model został wykonany z uwzględnieniem wszystkich zmiennych włączonych do modelu. Model został wykonany za pomocą funkcji glm(). Wynik funkcji podsumowującej stworzony model został przedstawiony na rysunku poniżej. Do jego stworzenia wykorzystałem funkcję summary().
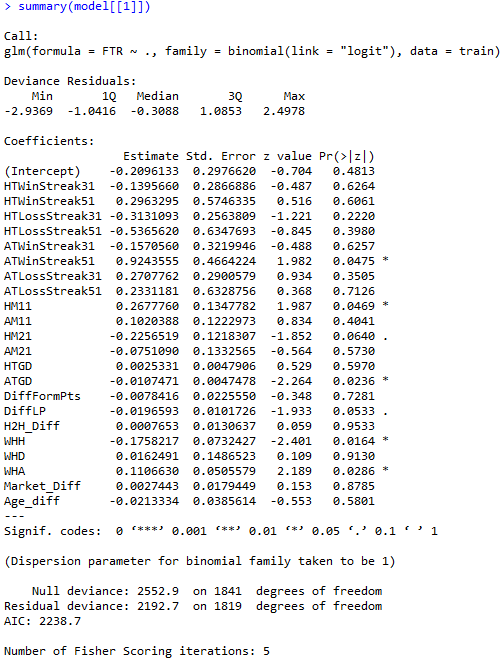
W modelu tym wykorzystane zostały wszystkie zmienne zawarte w zbiorze danych. Na górze przedstawionego output’u widnieje postać modelu regresji logistycznej dla tego zadania, poniżej natomiast współczynniki dla każdej ze zmiennych. Istotnym zagadnieniem jest badanie kolejnych zmiennych pod względem ich istotności statystycznej. Pierwsza kolumna od prawej wskazuje włąsnie na istotność danej zmiennej w modelu. Dla łatwiejszej interpretacji podane zostały „*” obok kategorii zmiennych istotnych statystycznie na odpowiednich poziomach: „***” – oznaczają istotność statystyczną na poziomie 0,001, „**” – na poziomie 0,01, „*” – na poziomie 0,05. Zmienne „WHH”, „WHA” , „DiffLP”, „ATGD”, „ATWinSstreak5”, „HM1” na poziomie istotności równym 0.05 są statycznie istotne, więc ich interpretacja jest uzasadniona.
Przykładowo, dla zmiennej HTLossStreak5 oszacowany parametr wynosi 0.840518. Aby określić szanse dla tej kategorii należy skorzystać ze wzoru: e^współczynnik . Dzięki takiemu przekształceniu otrzymane zostaną wartości szans dla odpowiednich zmiennych. Co to oznacza? e^0,840518 = 1,2621218. Przy przyjęciu wartości 1 przez zmienną „HTLossStreak5 ”, szanse na przyjęcie przez zmienną FTR wartości 1 wynoszą 1,2621218, co oznacza, że przy założeniu niezmienności innych parametrów, mecz, w którym drużyna gospodarzy ma serię 5 porażek z rzędu (HTLossStreak3 = 1), ma 26% większe szanse na wygraną w analizowanym spotkaniu niż w sytuacji, gdyby zmienna HTLossStreak3 przyjęłaby wartość 0. Innymi słowy, drużyna gospodarzy mająca 5 porażek rzędu jest o ponad 26% bardziej skłonna wygrać l swój następny mecz, niż gdyby tak złej serii nie miała. Ciekawy wniosek.
Jak widać z poprzedniego zrzutu z ekranu tylko kilka zmiennych jest istotnych statystycznie, co skutkuje tym, iż dla całej reszty pozostałych zmiennych nie ma podstaw do interpretacji. W rezultacie należałoby stworzyć model, który jest znacznie bardziej okrojony i uwzględnia wyłącznie statycznie istotne zmienne. Do tego celu wykorzystałem funkcję step() z wykorzystaniem regresję postępująca, inaczej zwanej metodą dołączenia (ang. forward), do wyboru kolejnych zmiennych. W skrócie polega to na tym , że na początku tworzony jest model bez żadnej zmiennej, następnie dołączana jest kolejna zmienna, tak aby polepszyć jakość modelu. Kiedy dołączenie następnej zmiennej nie przynosi oczekiwanego efektu algorytm zwraca optymalną postać modelu. Finalnie po wykorzystaniu tej funkcji otrzymujemy taka postać modelu :
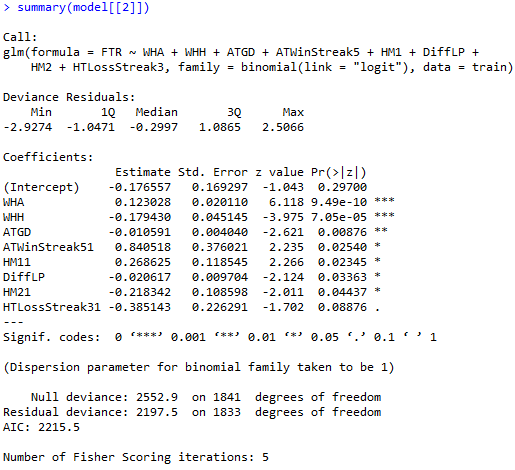
Jak widać, zmiennych w tym modelu jest znacznie mniej a ponadto prawie każda z nich jest istotna statycznie. Wszystkie zmienne, poza zmienną „HTLossStreak3”, wykorzystane w modelu są istotne statycznie na poziome istotności α = 0.05. Kategoria zmiennej HTLossStreak3 przyjmująca wartość 1 również jest istotna statystycznie, jednak dla poziomu istotności wynoszącego 0,1. Ponadto, należy zaznaczyć, że wartość kryterium informacyjnego AIC w modelu 2 zmalała w porównaniu do pierwszego. Oznacza to, że usunięcie zmiennych nieistotnych statystycznie wpłynęło pozytywnie na postać modelu, a więc „sumarycznie rzecz ujmując, wszystkie wprowadzone zmienne i ich kategorie „zarabiają na siebie” informacją, którą wnoszą” .
Szanse przedstawiają się sposób następujący:

Źródło: Opracowanie własne.
Interpretacja każdego z otrzymanych współczynników:
- Przy zachowaniu niezmienności pozostałych zmiennych wzrost kursu na drużynę gości o jedną jednostkę (WHA) sprawia, że dana obserwacja ma 13% większe szanse na wygraną drużyny gospodarzy. Jest to wniosek intuicyjny, z racji faktu, że im większy kurs na drużynę przyjezdnych, tym mniejsze szanse na zwycięstwo przez tę drużynę w danym meczu.
- Przy wzroście kursu na drużynę gospodarzy (WHH) o jedną jednostkę, szansę na zwycięstwo w tym meczu przez tę drużynę są o 16,4% (1-0,8357) niższe, przy zachowaniu wszystkich pozostałych zmiennych na tym samym poziomie.
- Przy wzroście różnicy strzelonych bramek do straconych dla drużyny gości o jedną jednostkę, szansę na zwycięstwo w danym meczu maleją o około 1 %. Bardzo ciekawy i nieintuicyjny wniosek.
- Drużyna gospodarzy, która gra przeciwko drużynie gości, która 5 ostatnich meczów wygrała ma o 230% większe szansę na zwycięstwo niżeli przyjezdni by takiej serii nie mieli!!!
- Drużyny gospodarzy, które wygrały swój poprzedni mecz, mają o 31% większe szanse na zwycięstwo w danym meczu, niżeli drużyny, które ostatniego meczu nie wygrały. W dalszym ciągu przy niezmienności pozostałych cech.
- Wraz ze wzrostem różnicy w pozycji w tabeli z poprzedniego sezony, drużyna gospodarzy ma o około 2 % mniejsze szansę na zwycięstwo. Inaczej mówiąc drużyna gospodarzy pewniej wygra mecz z drużyną, która była bliżej nich w tabeli niżeli odwrotnie. Kolejny bardzo ciekawy wniosek.
- Szanse na zwycięstwo drużyny gospodarzy są o 20% niższe w przypadku kiedy drużyna gości wygrała ta wygrała swój przed ostatni mecz, przy zachowaniu niezmienności parametrów pozostałych zmiennych
- Szanse na zwycięstwo drużyny gospodarzy są o ok. 32% niższe, jeżeli drużyna ta zaliczyła serię 3 porażek z rzędu w ostatnich meczach w porównaniu do drużyny, która takiej złej passy nie miała, przy zachowaniu identycznych wartości pozostałych zmiennych.
Przyznam się szczerze, że niektóre wnioski mnie bardzo zaskoczyły. Ale tym lepiej, zawsze dowiadujemy się czegoś nowego. Tak przedstawiają się liczby.
Badanie jakości modelu
W celu określenia jakości modelu oraz dopasowania się go do danych zbudowane zostały dwie krzywe ROC. Porównane tym samym zostały ze sobą dwa stworzone modele.
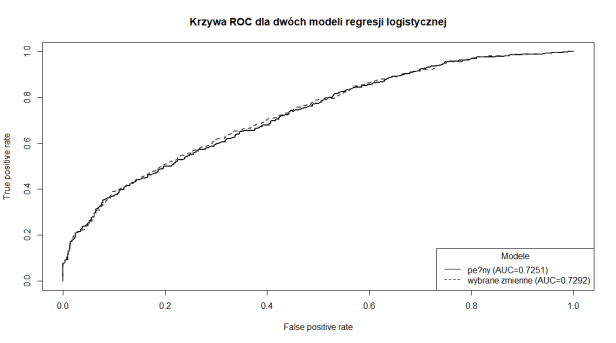
Obie krzywe są bardzo podobne do siebie. Świadczy to o bardzo zbliżonej jakości do siebie. Model z wybranymi zmiennymi pod względem istotności zmiennych okazał się niewiele lepszy od tego, który wykorzystał wszystkie zmienne ze zbioru danych. Co do interpretacji powyższego wykresu, głównie interesuje nas pole pod krzywą ROC, zwane AUC (ang. area under curve). Teoria dotycząca interpretacji krzywej ROC znajduje możecie podejrzeć tu. Miara ta wykorzystywana jest do badania jakości modelu, a więc im wartość bliższa 1, tym lepiej. W naszym przypadku jakość modelu jest oszacowana na poziomie 0,73 , co jest wynikiem akceptowalnym biorąc pod uwagę duży wachlarz możliwości co do rozszerzenia modelu. Istnieje przecież bardzo wiele potencjalnie istotnych zmiennych, które można by wykorzystać. Może jakieś pomysły ?
Wynikami, które powstają w wyniku działania stworzonego modelu są wartości jakie przyjmuje zmienna FTR, czyli wynik końcowy spotkania. Poniżej przedstawiono schematyczną postać funkcji regresji logistycznej, którą wykorzystuje algorytm przy stworzeniu modelu.

Mimo iż zmienna ta przyjmuje dwie kategorie, 0 – w przypadku remisu lub wygranej gości lub 1 – w przypadku wygranej gospodarza, wartości wynikowe mieszczą się w zakresie <0;1> i przykładowo przedstawiają się następująco:

Wyniki naszego modelu rozmieszczone są na krzywej w kształcie litery S. Czerwone kropki to końcowa wartość zmiennej objaśnianej, czyli wynik końcowy spotkania. To od badacza zależy, jaki dobierze parametry, aby przyporządkować odpowiednie wartości do odpowiedniej kategorii.
W przypadku powyżej przedstawione zostały wyniki dla 10 obserwacji, czyli dla jednej kolejki w Lidze Hiszpańskiej. Następnie istotny jest wybór punktu odcięcia dla otrzymanych wyników. Innymi słowy powyżej jakiej wartości dana obserwacja przyjmie wartość 1 ? W naszym przypadku zmienna celu rozkłada się prawie równomiernie, gdyż 52.8 % to obserwacje zaliczone do kategorii 0, reszta to – 1. Stosunek dwóch kategorii w przybliżeniu wynosi 1/1, dlatego też progiem odcięcia w naszym przypadku będzie po prostu wartość 0,5.
Weryfikacja modelu
W momencie tworzenia tego wpisu oraz kończenia wspomnionego modelu regresji logistycznej (tj. 14 września 2018) jesteśmy przed rozpoczęciem się 4 kolejki w La Lidze, dlatego też te mecze wezmę pod lupę. Wykorzystam mecze z tej kolejki do próby weryfikacji modelu.
W tym celu stworzyłem poniższą tabele, w której znajdziecie wszystkie mecze 4 kolejki La Liga. W kolumnie „prediction” znajdują się wartości otrzymane na podstawie modelu regresji logistycznej. W kolumnie „FTR_05” znajdują się zero jedynkowe wyniki zmiennej celu, czyli wyniku końcowego spotkania. Są to innymi słowy
| HomeTeam | AwayTeam | prediction | FTR_05 | |
| 1 | Huesca | Vallecano | 0.463179285674901 | Remis_lub_gosc |
| 2 | Ath Bilbao | Real Madrid | 0.225603931109078 | Remis_lub_gosc |
| 3 | Ath Madrid | Eibar | 0.653357144623841 | Gospodarz |
| 4 | Sociedad | Barcelona | 0.196443160879618 | Remis_lub_gosc |
| 5 | Valencia | Betis | 0.528264966343841 | Gospodarz |
| 6 | Espanol | Levante | 0.476519641533868 | Remis_lub_gosc |
| 7 | Leganes | Villarreal | 0.350793488078867 | Remis_lub_gosc |
| 8 | Sevilla | Getafe | 0.568544964619945 | Gospodarz |
| 9 | Valladolid | Alaves | 0.460725027805872 | Remis_lub_gosc |
| 10 | Girona | Celta | 0.512353016932247 | Gospodarz |
Aktualizacja
Wczoraj, czyli 14 września 2018, odbył się już pierwszy mecz z 4 kolejki ligi hiszpańskiej sezonu 2018/2019. Huesca na własnym stadionie podejmowała Rayo Vallecano. Przewidywanym wynikiem był remis lub wygrana gości (Remis_lub_gosc). Mecz zakończył się wynikiem 0:1, więc zgadza się z naszymi przewiadywaniami.
Na tę chwilę skuteczność modelu wynosi 1/1, jednak jeszcze 9 spotkań przed nami.
Aktualizacja 21-09-2018
Wartości przewidywane na najbliższą kolejkę La Liga 🙂
| HomeTeam | AwayTeam | prediction | FTR_05 | Wynik (24-09-2018) | |
| 1 | Huesca | Sociedad | 0.3251441588838 | Remis_lub_gosc | 0:1 |
| 2 | Celta | Valladolid | 0.4718528141236 | Remis_lub_gosc | 3:3 |
| 3 | Eibar | Leganes | 0.4895842013252 | Remis_lub_gosc | 1:0 |
| 4 | Getafe | Ath Madrid | 0.3130163630449 | Remis_lub_gosc | 0:2 |
| 5 | Real Madrid | Espanol | 0.7252373546101 | Gospodarz | 1:0 |
| 6 | Vallecano | Alaves | 0.4495536735581 | Remis_lub_gosc | 1:5 |
| 7 | Barcelona | Girona | 0.9496927006078 | Gospodarz | 2:2 |
| 8 | Betis | Ath Bilbao | 0.4826944397545 | Remis_lub_gosc | 2:2 |
| 9 | Levante | Sevilla | 0.3077138692086 | Remis_lub_gosc | 2:6 |
| 10 | Villarreal | Valencia | 0.4655916351046 | Remis_lub_gosc | 0:0 |
Podsumowując, w drugiej analizowanej kolejce ligi hiszpańskiej skuteczność modelu wyniosła zyskujące 80%. Wynik uzasadnia wykorzystanie regresji logistycznej w modelach predykcyjnych dla piłkarskich danych. Model pomylił się tylko i wyłącznie dwa razy, jednak należy wziąć pod uwagę bardzo mała liczbę obserwacji wchodzącą do zbioru testowego (10). Ciężko jest też określić, tak naprawdę, poziom skuteczności algorytmu dla wszystkich meczów w przyszłości.
Model na ten moment zostanie odsunięty na bok, gdyż przed nami wiele ciekawych i interesujących modeli uczenia maszynowego, który planuje przedstawić na tej stronie. Nie zapominamy oczywiście o wspomnianej „maszynce”, gdyż będę starał śledzić jak model sprawdza się w aktualnym sezonie 2018/2019.

Tak z ciekawości: w jaki sposób stworzyłeś te dodatkowe dane typu serie zwycięstw/porażek, wiek zawodników, etc?
PolubieniePolubienie
Informacje dotyczące budżetów, średniego wieku zawodników oraz liczby zagranicznych zawodników znalazłem na stronie, w tym przykładzie dla La Liga : https://www.transfermarkt.co.uk/laliga/startseite/wettbewerb/ES1 . Następnie stworzyłem skrypt, który webscarpujący tę stronę. Kod znajdziesz na moim githubie pod nazwą trasfer.R
Co do serii porażek i zwycięstw to również na podstawie wyników byłem w stanie stworzyć pętle, która dodaje taką wartość zmiennej dla danej obserwacji.
PolubieniePolubienie
Jak się tworzy modele, które mają ogarnąć całą rzeczywistość to efekt jest zawsze taki sam. A mianowicie słaby. Napracowałeś się to fakt. Do piłki nożnej trzeba mieć podejście bardziej probalistyczne. Tworzyć wzorzec, który ogarnie 10% rzeczywistości ale na 99%. A nie model,który ma dać odpowiedź jaki ma być wynik w każdym meczu, lecz ze skutecznością 60-80% i to wynik na zasadzie wygra zremisuje/przegra zremisuje., bo o dokładnym wyniku to można tylko marzyć. Już sama dwukrotna przewaga miejsca w tabeli daje 80-90% szans, że gospodarz wygra / zremisuje. Jeśli dodamy do tego wynik ostatniego meczu to mamy pewne 90%. Nie potrzeba korzystać z wartości rynkowych i skrapować gigabajtów niepotrzebnych danych 🙂
PolubieniePolubienie