
W wielu przypadkach potrzebowałem mechanizmu wyboru zmiennych do modelu, które zostaną wykorzystane. Często również, musiałem określić jaka zmienna najbardziej wpływa na wynik końcowy predykcji. Ponadto, jak bardzo dana zmienna jest istotna w modeli. Może czasami skupiałem się zbytnio nad zmienną, która tak naprawdę miała stosunkowo niską moc predykcyjną. Powodów dla tego wpisu można znaleźć więcej, jednak koniec końców postanowiłem usystematyzować wiedze oraz zasoby, które posiadam. Głównym powodem tego artykuły będzie zatem, jego wykorzystanie w przyszłości, kiedy zajdzie taka potrzeba – byśmy nie musieli się zastanawiać jak wybierać zmienne. Mam jednak nadzieję, że wyniesiecie z niego jak najwięcej a może sami uporządkujecie wiedze, uwzględniając to co już wiecie.
Dlaczego potrzebujemy sprawnego mechanizmu wyboru zmiennych?
Jeśli założylibyśmy, że wszystkie zmienne są jednakowo istotne dla modelu, zasadne byłoby pominięcie etapu selekcji. W rzeczywistości sytuacja taka zdarza się bardzo rzadko – więc praktycznie zawsze warto skupić się nad wyborem odpowiednich zmiennych do modelu. Rozważania na temat użyteczności tego etapu w modelowaniu najlepiej zacząć od podania pierwszego poważnego jej zastosowania. Selekcje zmiennych wykorzystuje się w głównej mierze do zredukowania ilości inputów w celu zmniejszenia kosztów przetwarzania oraz w często aby poprawić jakość dopasowania modelu. Innymi słowy działamy tak, aby przy tworzeniu modelu zostały nam właśnie te zmienne, które mają największą moc predykcyjną. Reszta zmiennych robi często wolny przebieg na etapie przetwarzania, a mimo to wykorzystuje często dużą część mocy obliczeniowej maszyny. Dzięki selekcji możemy w przejrzysty sposób zidentyfikować te zmienne, które są najważniejsze przy tworzeniu predykcji oraz zaoszczędzić czas i pieniądze.
Rodzaje algorytmów selekcji zmiennych
Jak możemy przeczytać w https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/ wyróżniamy dwa podstawowe rodzaje algorytmów selekcji zmiennych. Metody (1) Wrapper Feature Selection oraz (2) Filter Feature Selection.

(1) W pierwszym przypadku, tworzy się wiele modeli, różniących się miedzy sobą zmiennymi wejściowymi jakie zostały wybrane do jego budowy. Następnie na podstawie miar dokładności odpowiednich modeli wybierany zostaje zestaw najlepszych zmiennych. Może to przebiegać w dwóch konfiguracjach:
- Tworzymy model bez żadnych zmiennych a następnie dodajemy po jednej zmiennej sprawdzając jego miary dopasowania. Dodajemy nowe zmienne, aż dodanie kolejnej nie poprawia w sposób znaczący jakości modelu.
- Tworzymy model ze wszystkimi zmiennym, a następnie odejmujemy po jednej, ciągle sprawdzając miary modelu. W taki sposób możemy znaleźć odpowiedni zestaw kolumn dla naszego zbiór wejściowego do modelu.
Kolejność zmiennych dodawanych lub odejmowanych również ma istotne znaczenie. Generalnie przy tym sposobie selekcji zmiennych nie zawracamy sobie głowy rodzajem zmiennej (typu kategorycznego czy numerycznego) bo interesuje nas tak naprawdę ten docelowy zestaw zmiennych przy których otrzymujemy maksymalizację jakości modelu.
(2) Drugi grupa metod selekcji zmiennych wykorzystuje techniki statystyczne do oszacowania związku każdej ze zmiennych niezależnych (wejściowych) ze zmienną zależną (wynikową). Na podstawie danej statystyki możemy więc odfiltrować te, które mają niesatysfakcjonującą wartości danej statystyki. Przy wykorzystaniu tej grupy metod musimy zwrócić uwagę na rodzaj zmiennej.
Sprawdźmy zatem jak przedstawia się ta metoda na danych piłkarskich, które w dalszym ciągu analizujemy. Naszą zmienną wynikową jest zmienna typu kategorycznego, natomiast jeśli chodzi o zmienne wejściowe – w zbiorze danych posiadamy praktycznie cały przekrój typów zmiennych. Zerknijmy na dane pobrane z bazy danych RC2 na AWS:
import pandas as pd
import os
import time
import pymysql
import psycopg2
import sklearn
loc_to_functions = "D:\data_football\Football_prediction_ML\Football_ML"
os.chdir(loc_to_functions)
import functions_for_dataset_preparation as f1
league_abb = 'SP1'
connection_aws = psycopg2.connect(user = "####",
password = "####",
host = "####",
port = "5432",
database = "####")
dataset = pd.read_sql('SELECT * FROM public."'+league_abb+'" WHERE "FTHG" is NOT NULL AND "FTAG" is NOT NULL', connection_aws)
dataset["Date"] = pd.to_datetime(dataset.Date , format = "%Y-%m-%d")
marketv = pd.read_sql('SELECT * FROM public."budget_'+league_abb+'"', connection_aws)
df_final = f1.dataset_preparation(dataset, league_abb, marketv)
df_final = df_final.drop('Mean_away_goals',axis=1)
df_final = df_final.dropna()
df_final.tail()
| HTGD | ATGD | HTWinStreak3 | HTWinStreak5 | HTLossStreak3 | HTLossStreak5 | ATWinStreak3 | ATWinStreak5 | ATLossStreak3 | ATLossStreak5 | DiffPts | DiffFormPts | DiffLP | Mean_home_goals | H2H_Diff | ELO_diff | Total_Diff | LP_Diff | FTR | Goals_mean_diff | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4657 | 0.259259 | -0.666667 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 18 | -1.0 | 1 | 1.41429 | 9 | 101 | 1.982210 | -12 | 0 | 0.80192 |
| 4658 | -0.296296 | 0.074074 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -5 | 0.0 | 8 | 0.96980 | 3 | -116 | 0.405778 | 5 | 0 | -0.00999 |
| 4659 | -0.333333 | -0.037037 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -10 | 1.0 | 7 | 2.59286 | -9 | -126 | 0.182038 | 7 | 0 | 1.98049 |
| 4660 | 1.185185 | 0.444444 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | -3.0 | -8 | 5.02857 | 3 | 249 | 3.550678 | -4 | 1 | 4.00795 |
| 4661 | -0.259259 | 0.037037 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -5 | -1.0 | 0 | 1.41429 | 3 | 52 | 3.056716 | 4 | 0 | 1.10810 |
- Zmienne typu numeryczne: HTGD, ATGD, DiffPts, DiffFormsPts, DiffLP, Mean_home_goals, HWG_Diff, ELO_diff, Total_Diff, LP_Diff, Goals_mean_diff.
- Zmienne zarówno typu integer jak i float.
- Dodatkowo posiadamy również zmienne typu kategorycznego, HTWinnStreak3, … , ATLossStreak5, przyjmujące dwie kategorie 0/1, które mogą również zostać za uznane za rodzaj zmiennej logicznej po uprzednim przekonwertowaniu.
Podział zbioru na X oraz y
df_final["FTR"] = df_final["FTR"].astype('category')
X, y = df_final.drop('FTR',axis=1).reset_index(drop = True), df_final['FTR'].reset_index(drop = True)
Zmienne wejściowe numeryczne, zmienna wyjściowa kategoryczna – ANOVA
Wyłącznie zmienne numeryczne ze zbioru danych.
df_final.select_dtypes(include='number').head(2)
| HTGD | ATGD | DiffPts | DiffFormPts | DiffLP | Mean_home_goals | H2H_Diff | ELO_diff | Total_Diff | LP_Diff | Goals_mean_diff | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.5 | -2 | 0.0 | 5 | 1.6 | 0 | 27 | 1.47931 | 5 | 0.45 |
| 1 | 0.0 | 0.5 | -2 | 0.0 | 5 | 1.6 | 0 | 27 | 1.47931 | 5 | 0.45 |
from sklearn.feature_selection import f_classif
f_classif(X.select_dtypes(include='number'), y)[0]
array([273.89813418, 294.55492913, 442.81969671, 247.88494511,
864.00595966, 130.29097375, 215.37539977, 773.43604339,
384.68533162, 263.26943018, 131.72880132])
f_classif zwaraca dwie tablice:
- Zbiór wartości statystyki F pomiędzy poszczególnymi zmiennymi a zmienną wyjściową
- Zbiór wartości p-value dla danej statystyki F poszczególnej zmiennej
pd.DataFrame({"Veriables" : X.select_dtypes(include='number').columns,
"F_stat":f_classif(X.select_dtypes(include='number'), y)[0],
"p_value":f_classif(X.select_dtypes(include='number'), y)[1]})
| Veriables | F_stat | p_value | |
|---|---|---|---|
| 0 | HTGD | 273.898134 | 7.943703e-60 |
| 1 | ATGD | 294.554929 | 4.545048e-64 |
| 2 | DiffPts | 442.819697 | 5.481588e-94 |
| 3 | DiffFormPts | 247.884945 | 1.860410e-54 |
| 4 | DiffLP | 864.005960 | 2.275804e-174 |
| 5 | Mean_home_goals | 130.290974 | 8.773028e-30 |
| 6 | H2H_Diff | 215.375400 | 1.055697e-47 |
| 7 | ELO_diff | 773.436043 | 1.276298e-157 |
| 8 | Total_Diff | 384.685332 | 2.297429e-82 |
| 9 | LP_Diff | 263.269430 | 1.231137e-57 |
| 10 | Goals_mean_diff | 131.728801 | 4.336944e-30 |
Wartość statystyki F dla poszczególnej zmiennej sprawdza nam, czy pogrupowane zbiory danej zmiennej na podstawie kategorii zmiennej wyjściowej, mają statystycznie znacząco różne średnie. Inaczej mówiąc, dzielimy daną zmienną na podstawie grup wynikowych i badamy w tych grupach średnie, następnie sprawdzamy na podstawie testu czy są one od siebie statystycznie różne.
from sklearn.feature_selection import SelectKBest
fs = SelectKBest(score_func=f_classif, k=5)
X_selected = fs.fit_transform(X.select_dtypes(include='number'), y)
X.select_dtypes(include='number').columns[fs.get_support()]
Index(['ATGD', 'DiffPts', 'DiffLP', 'ELO_diff', 'Total_Diff'], dtype='object')
Zmienne wejściowe kategoryczne, zmienna wyjściowa kategoryczna
from sklearn.feature_selection import chi2
df_final.select_dtypes(include='category').tail(2)
Wyłącznie zmienne typu kategorycznego
| HTWinStreak3 | HTWinStreak5 | HTLossStreak3 | HTLossStreak5 | ATWinStreak3 | ATWinStreak5 | ATLossStreak3 | ATLossStreak5 | FTR | |
|---|---|---|---|---|---|---|---|---|---|
| 4660 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4661 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
pd.DataFrame({"Veriables" : X.select_dtypes(include='category').columns,
"F_stat":chi2(X.select_dtypes(include='category'), y)[0],
"p_value":chi2(X.select_dtypes(include='category'), y)[1]})
| Veriables | F_stat | p_value | |
|---|---|---|---|
| 0 | HTWinStreak3 | 34.115387 | 5.193893e-09 |
| 1 | HTWinStreak5 | 47.634346 | 5.136071e-12 |
| 2 | HTLossStreak3 | 8.542965 | 3.468601e-03 |
| 3 | HTLossStreak5 | 4.716147 | 2.988063e-02 |
| 4 | ATWinStreak3 | 72.472202 | 1.694013e-17 |
| 5 | ATWinStreak5 | 45.034120 | 1.936311e-11 |
| 6 | ATLossStreak3 | 14.960250 | 1.098000e-04 |
| 7 | ATLossStreak5 | 8.823058 | 2.974478e-03 |
Jak znajdziemy napisane na oficjalnej dokumentacji SelectKBest wartości te mogą zostać wykorzystane do wyboru dowolnej ilości zmiennych (podanych w parametrze) z największą wartości statystyki testu chi-kwadrat z X, która może zawierać wyłącznie nieujemne wartości zmiennej. Taką zmienną może być zarówno zmienna typu kategorycznego lub logicznego.
from sklearn.feature_selection import SelectKBest
chi = SelectKBest(score_func=chi2, k=2)
X_selected = chi.fit_transform(X.select_dtypes(include='category'), y)
X.select_dtypes(include='category').columns[chi.get_support()]
Index(['HTWinStreak5', 'ATWinStreak3'], dtype='object')
Zaawansowane metody selekcji zmiennych
Inspiracja pochodzi z https://machinelearningmastery.com/calculate-feature-importance-with-python/
Zaczniemy od modelu liniowego dla klasyfikacji. Generalnie, predykcja na podstawie modelów liniowych dokonuje się poprzez budowę algorytmu jako sumę zmiennych wejściowych przemnożoną przez ich odpowiednie wagi (współczynniki). Wagami w naszym przypadku mogą być ich wartości istotności zmiennej. Zatem, im większa wartość współczynnika przy danej zmiennej – tym będzie ona miała większy wpływ na wyjściową predykcję.
Sprawdźmy na początku jak kreują się współczynniki istotności zmiennych przy budowaniu modelów liniowych.
Selekcja zmiennych za pomocą Regresji Logistycznej
from sklearn.linear_model import LogisticRegression
model_lr = LogisticRegression(solver='lbfgs',max_iter=1000)
model_lr.fit(X, y)
lr = pd.DataFrame({"Zmienna" : X.columns,
"Wartość istotnosci":model_lr.coef_[0]})
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6))
sns.set(style="whitegrid")
ax = sns.barplot(x="Zmienna", y="Wartość istotnosci", data=lr)
for label in ax.get_xticklabels():
label.set_rotation(45)
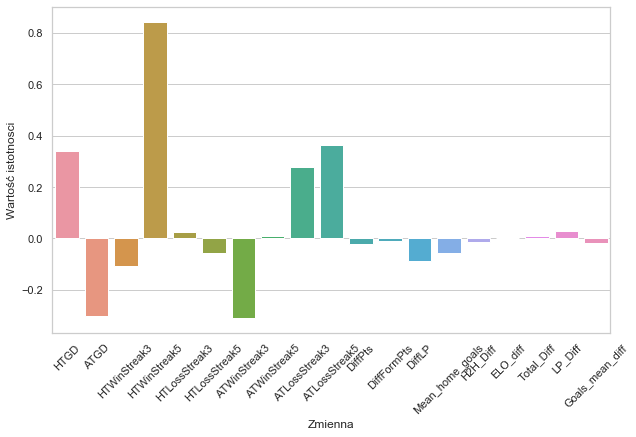
Aby lepiej przyjrzeć się wynikom – podzielę zmienne wejściowe na kategoryczne i numeryczne – tak jak zrobione zostało w części pierwszej materiału.
model_lr_n = LogisticRegression(solver='lbfgs',max_iter=1000)
model_lr_n.fit(X.select_dtypes(include='number'), y)
lr_n = pd.DataFrame({"Zmienna" : X.select_dtypes(include='number').columns,
"Wartość istotnosci":model_lr_n.coef_[0]})
model_lr_c = LogisticRegression(solver='lbfgs',max_iter=1000)
model_lr_c.fit(X.select_dtypes(include='category'), y)
lr_c = pd.DataFrame({"Zmienna" : X.select_dtypes(include='category').columns,
"Wartość istotnosci":model_lr_c.coef_[0]})
f, axes = plt.subplots(1, 2, figsize=(15,5))
sns.barplot(x="Zmienna", y="Wartość istotnosci", data=lr_c , ax=axes[0])
sns.barplot(x="Zmienna", y="Wartość istotnosci", data=lr_n, ax=axes[1])
for ax in f.axes:
for label in ax.get_xticklabels():
label.set_rotation(45)

Według modelu regresji logistycznej, zmienne kategoryczne mają bardzo znaczący wpływ na wyniki predykcji. Szczególnie zmienna HTWinSrea5 oraz ATWinsStreak3 i 5. Jeśli natomiast mowa o zmiennych numerycznych, tutaj zdecydowane na tle reszty wyróżniają się zmienne reprezentujące różnicę goli strzelonych i straconych odpowiednio dla gospodarzy (HTGD) oraz gości (ATGD) przeskalowaną przez wartość kolejki w sezonie. Przyznam się szczerze, że dosyć kontrowersyjne są to wyniki biorąc pod uwagę wcześniejszą znajomość modelów. Sprawdźmy jednak jak prezentują się pozostałe modele.
Selekcji według drzewa decyzyjnego
Przejdźmy zatem do modelu drzewa decyzyjnego, i sprawdźmy jak on podchodzi do naszych zmiennych.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X, y)
dt = pd.DataFrame({"Zmienna" : X.columns,
"Wartość istotnosci": model.feature_importances_})
plt.figure(figsize=(10,6))
sns.set(style="whitegrid")
ax = sns.barplot(x="Zmienna", y="Wartość istotnosci", data=dt)
for label in ax.get_xticklabels():
label.set_rotation(45)
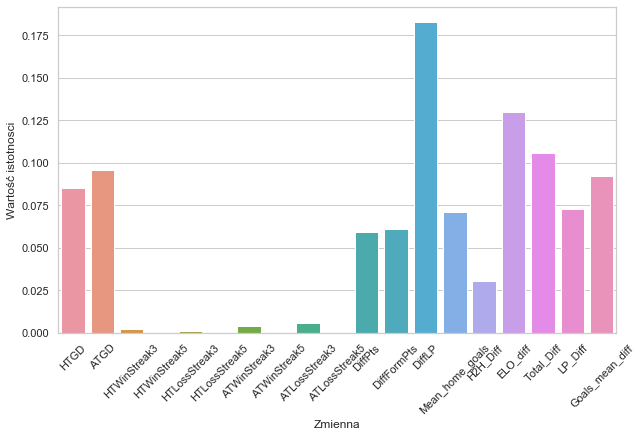
Intuicyjnie te wyniki przedstawiają się bardzo dobrze. Są również bardzo zbliżone do tych otrzymanych z oszacowania algorytmu ANOVA dla tego zbioru danych. Warto zauważyć, że zmienne typu kategorycznego mają praktycznie znikomą istotność w porównaniu z całą resztą zmiennych numerycznych.
Selekcja zmiennych według modelu Las losowy – random forest
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)
model.fit(X, y)
rf = pd.DataFrame({"Zmienna" : X.columns,
"Wartość istotnosci": model.feature_importances_})
plt.figure(figsize=(10,6))
sns.set(style="whitegrid")
ax = sns.barplot(x="Zmienna", y="Wartość istotnosci", data=rf)
for label in ax.get_xticklabels():
label.set_rotation(45)

Wyniki zbliżone do tych otrzymanych za pomocą drzewa decyzyjnego z tą różnicą, że zarówno zmienna ELO_diff oraz Total_diff zyskały na istotności w stosunku do pozostałych. Pierwsza z nich reprezentuje różnicę w rankingu punktów ELO, druga natomiast to stosunek wartości budżetów obu klubów.
Selekcja zmiennych według modelu klasyfikacyjnego XBoost
Przed budową tego modelu musimy przekonwertować zmienne kategoryczne na zmienne typu logicznego.
cols_to_cv = ['HTWinStreak3', 'HTWinStreak5', 'HTLossStreak3',
'HTLossStreak5', 'ATWinStreak3', 'ATWinStreak5',
'ATLossStreak3', 'ATLossStreak5']
for col in cols_to_cv:
X[col] = X[col].astype('bool')
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X, y)
xb = pd.DataFrame({"Zmienna" : X.columns,
"Wartość istotnosci": model.feature_importances_})
plt.figure(figsize=(10,6))
sns.set(style="whitegrid")
ax = sns.barplot(x="Zmienna", y="Wartość istotnosci", data=xb)
for label in ax.get_xticklabels():
label.set_rotation(45)

Według stworzonego modelu klasyfikatora XGBoost największą istotnością wykazują się następujące zmienne: DiffLP, ATWinStreak5 oraz ELO_diff. Wartości istotności większości pozostałych zmiennych oscyluje przy podobnej wartości.
Podsumowanie
Przedstawiłem w tym artykule różne, praktyczne sposoby selekcji zmiennych wybranych do modelu oraz ich implementację w pythonie. Użyteczność takich działań – jak sami zresztą zauważyliście – jest bardzo duża. Rozpoczynając od określenia zmiennych, które mają największy wpływ na wartość wyjściową poprzez zrozumienie danych wejściowych i wyciągniecie „predykcyjnych” wniosków. Jak można zauważyć, praktycznie wszystkie z tych sposobów dawały rożne zestawy najlepszych zmiennych. Ta własność jest zatem kluczowa do zdefiniowania stwierdzenia, że nie ma jednego najlepszego sposobu wyboru zmiennych. Chciałoby się powiedzieć – to zależy. Dokładnie, to zależy od (1) problemu przed jakim stoimy, od (2) rodzaju oraz (3) charakterystyki zmiennych wejściowych ale również od tego (4) jak przedstawia się zmienna wyjściowa. Często trudno się w tym połapać, który sposób dla nas będzie najlepszy ale zazwyczaj warto sprawdzić więcej niż jeden sposób aby się przekonać. Przede wszystkim dlatego, że analizując poszczególne wyniki algorytmów dostajemy nową informację na temat danych. To w kontekście predykcji jest istotne, ponieważ zazwyczaj rzuca nam nowe światło na rożne aspekty zagadnienia. Nowa informacja bywa bezcenna w procesie analizy danych!

Mam nadzieję, że się nie opwtarzam z tym komentarzem, ale pisałem magisterkę o doborze zmiennych do liniowych modeli. Wygenerowałem ileś równań. Do wyniku każdego z nich dodawałem szum (chyba z rozkładu normalnego). A potem szukałem takiej metody, która najlepiej zgadła pierwotnie użyte do wygenerowania wyników zmienne objaśniające. Najlepsze wyniki dawały metody oparte o RSS (AIC i BIC). Krokowe były słabe. Ja posługiwałem się delphi (15 lat temu – ciekawe czy słyszałeś o takim środowisku 🙂 ) i wspierałem excelem. Dziś, gdy jest python pewnie można to wszystko jeszcze łatwiej i szybciej policzyć dlatego też sądzę, że metody krokowe powinny odejść do lamusa, bo nawet w przypadku 10 zmiennych trzeba zbudować 1024 modele (1023 wyłączając model y = b), co dobrym maszynom przy jakoś ograniczonej masie danych wejściowych powinno zająć mało czasu.
Z tego wyliczyłbym jakąś rozsądną metrykę i nie zawracał sobie głowy krokami, zwłaszcza, że kroki potrafią dobrać zmienną, która będzie gorsza od zestawu 2 innych lub odwrotnie (koincydencja).
PolubieniePolubienie