
Pozostając w temacie uczenia maszynowego i wykorzystania tych algorytmów
Motywacja i idea
Idąc za ciosem zadowalających wyników jakie otrzymaliśmy za pomocą regresji logistycznej przy przewidywaniu wyników końcowych, przejdziemy tym razem do kolejnego narzędzia uczenia maszynowego – drzewa decyzyjnego. Sam algorytm daje wielkie możliwości a przy tym jest bardzo intuicyjny i prosty w interpretacji. 
Drzewo decyzyjne jest rodzajem algorytmu uczenia nadzorowanego (inaczej zwanego uczenia „z nauczycielem”), czyli takiego w którym z góry zdefiniowana jest zmienna celu, a zatem ta, która jest modelowana, która nas interesuje. W naszym przypadku zmienną celu jest zmienna określająca wynik końcowy spotkania (wygrana drużyny gospodarzy albo remis lub wygrana gości, przyjmująca odpowiednio wartości 1 lub 0). Algorytm ten jest głównie wykorzystywany do rozwiązywania problemów klasyfikacyjnych, a więc takich jak nasz 🙂 . Taki rodzaj drzewa nazywamy klasyfikacyjnym drzewem decyzyjnym. Innym typem są regresyjne drzewa decyzyjne. Ponadto, podobnie jak w regresji logistycznej, możemy wykorzystywać zarówno zmienne kategoryczne jak i ciągłe. Zmienna kategoryczna w naszym zbiorze danych to np. fakt wygrania ostatniego meczu przez daną drużynę (0/1), natomiast przykład zmiennej ciągłej to różnica bramek strzelonych i straconych dla danej drużyny ( .., -1, 0, 1, 2, …). Działanie drzewa decyzyjnego, w dużym uproszczeniu, polega na podziale zbioru treningowego, czyli części zbioru danych wydzielonego na potrzeby uczenia modelu, na dwa lub więcej homogenicznych podzbiorów wykorzystując do tego celu wartości danej zmiennej. Mówiąc inaczej, algorytm drzewa decyzyjnego przypomina grę w „Zgadnij kto to?”. Przy założeniu, że wszystkie cechy są binarne (mają tylko dwie kategorie), zadając odpowiednie pytania możemy odgadnąć jaką postać posiada przeciwnik. Tak też jest i w tym przypadku, wrzucając kolejne obserwacje do odpowiednich podzbiorów określonych na podstawie pewnych cech możemy określić wartość oczekiwanej zmiennej.
Jeżeli dalej wydaje się to skomplikowane , to już spieszę z przykładem , który powinien rozwiać wszelkie wątpliwości.
Wstęp do drzewa decyzyjnego
Weźmy oto taki przykład, chcemy przewidzieć czy dana osoba jest wysportowana. Do dyspozycji mamy takie cechy jak : wiek, zwyczaje żywnościowe, aktywność fizyczna i inne. W efekcie działania algorytmu otrzymujemy poniższe binarne drzewo decyzyjne.

Pytania (Wiek<30 ?, Ćwiczy o poranku ?) odpowiadają węzłom w drzewie. Liśćmi natomiast, są wartości zmiennej wynikowej, czyli „Niewysportowany” oraz „Wysportowany”. W tym przypadku wynikami są tylko dwie kategorie, czyli drzewo jest binarne. Pytanie umieszczone na samym wierzchołku drzewa nazywane jest jego korzeniem.
W przedstawionym przykładzie algorytm ten pomaga rozdzielić osoby o podanych cechach na te wysportowane i niewysportowane. Oczywiście posłużyłem się tu bardzo duży uproszczeniem, jednak na potrzeby wprowadzenia uważam, że przykład jest intuicyjny i choć trochę pomógł w zrozumieniu algorytmu drzewa decyzyjnego.
Homogeniczność i entropia
Tak wiem, ktoś mógłby powiedzieć, że taki podział, jak przedstawiony w przykładzie, nie zawsze prowadzi do poprawnych i tych samych wniosków. To, że ktoś je dużo pizzy, lub nie ćwiczy o pranku nie oznacza, że jest niewysportowany. Oczywiście, takie przypadki się zdarzą jednak przy konstruowaniu drzewa decyzyjnego w głównej mierze chodzi o podział na jak najbardziej homogeniczne podzbiory. Jest to o tyle kluczowe, iż przy założeniu, że zmienna wynikowa ma dwie kategorie, każdy liść końcowy powinien zawierać, kolokwialnie mówiąc, jak największy procent danej kategorii. Liście, które zawierają wartości zmiennej kategorii w proporcji 1/1 ( w naszym przypadku, 50 % meczów wygranych oraz 50% meczów niewygranych ) są dosłownie mówiąc bezużyteczne. Co to za podział, który daje nam 50-procentowe szanse znalezienia się w danym liściu przy dwóch kategoriach zmkennej? Celem działania drzewa decyzyjnego jest znalezienie takiego podziału , aby idealnie, znalazły się tam obserwacje tylko z jedną wartością zmiennej celu. I tu pojawia się zagadnienie entropii…
Entropia jest miara niejednorodności w zbiorze. Głównym założeniem przy konstruowaniu drzewa decyzyjnego jest minimalizacja entropii, czyli doprowadzenie do jak najbardziej jednorodnego podzbioru. Perfekcyjne drzewo decyzyjne doprowadziłoby do stworzenia wyłącznie jednorodnych podzbiorów, do których wpadły obserwacje wyłącznie z taką samą wartością modelowanej zmiennej.
Przy działaniu analizowanego modelu wykorzystywany jest algorytm ID3, który wykorzystuje wyliczoną entropię do oszacowania homogeniczności próby. Jeżeli dany zbiór jest całkowicie homogeniczny, entropia jest równa zero, natomiast jeżeli próba jest idealnie podzielona (np. na dwie części) entropia wynosi 1.

Jak widzimy na rysunku, nas najbardziej będą interesowały wartości entropii bliskie 0. Poniżej schematu jest przedstawiona wartość entropii przy równym podziale dwóch wartości analizowanej zmiennej, czyli p = 0,5. W takim przypadku entropia równa się 1 i jest to kolokwialnie mówiąc beznadziejny podział, który nie daje użytecznej informacji.
Obliczając wartość entropii każdego z atrybutów jesteśmy również w stanie oszacować ich informację dodaną (ang. information gain). Informacja dodana oszacowuje oczekiwaną redukcję wartości entropii poprzez wykorzystanie danej cechy. Innymi słowy, ile i co wnosi podział według kolejnej zmiennej . Mówiąc jeszcze inaczej, wartość ta określa nam zmienne, które najlepiej dzielą zbiór danych czyli na jak najbardziej homogeniczne podzbiory. Do przykładu sposobu oszacowania informacji dodanej odsyłam pod link.
Podsumowując działanie drzewa decyzyjnego, wyróżniamy następujące etapy przy ich konstruowaniu:
- Obliczenie wartości entropii danego zbioru,
- Podział zbioru w oparciu o wartości dane cechy (zmiennej). Oszacowanie entropii dla każdego podziału. Następnie są one proporcjonalnie sumowane w celu otrzymania całkowitej wartości entropii podziału. Otrzymana entropia jest odejmowana od entropii przed podziałem. Wynikiem jest wartością informacji dodanej, inaczej redukcji w wartości entropii,
- Wybór cechy z największą wartością informacji dodanej i powtórzenie działania dla każdej z gałęzi drzewa,
- a) Gałąź z wartością entropii równej 0 staje się liściem.
b) Gałąź z entropią większa od 0 potrzebuje dalszego podziału, - Algorytm ID3 działa kolejno na każdej gałęzi nie będącej liściem, aż obserwacje zostaną sklasyfikowane.
Źródło : https://www.saedsayad.com/decision_tree.htm
Podsumowanie algorytmu klasyfikacyjnego drzewa decyzyjnego
Mam nadzieję, że tym opisem przedstawiłem sposób i schemat działania drzewa decyzyjnego. Po przeanalizowaniu danych piłkarskich i opisaniu otrzymanych wyników wyda się to jeszcze bardziej proste i zrozumiałe. Narzędzie to jest zatem znacznie bardziej łatwiejsze i intuicyjne w interpretacji aniżeli analizowany wcześniej model regresji logistycznej. Ponadto, algorytm może być wykorzystywany zarówno do problemów regresyjnych dla zmiennej wynikowej ciągłej ( regresyjne drzewo decyzyjne) oraz problemów klasyfikacyjnych (klasyfikacyjne drzewo decyzyjne). Algorytm ten jest również znacznie bardziej zrozumiały w interpretacji jeżeli chodzi o wizualizacje jego wyników. Znacznie bardziej poprawia to komunikację, kiedy analityk chce przedstawić wyniki dla np. menadżerów. Poza tym wszystkim, wykorzystuje względnie minimalną ilość mocy obliczeniowej, co staje się nie lada możliwością przy tworzeniu bardziej rozbudowanych modeli. Dla mnie osobiście wielkim plusem drzewa decyzyjnego jest brak konieczności normalizowania zmiennych przed stworzeniem modelu, a to tym samym wpływa na ułatwioną interpretacje wyników.
Z drugiej zaś strony znacznym minusem tego algorytmu jest jego słoność do przeuczenia. Przeuczenia, czyli zbyt dobrego dopasowania się do danych na, których był tworzony model, a to tym samym odbija się na mniejszej skuteczności predykcyjnej na niezależnym zbiorze testowym. Na szczęście jesteśmy w stanie nad tym zapanować poprzez przycinanie stworzonego drzewa. Im „głębsze” drzewo tym szansa na przeuczenie jest większa, także poprzez zabieg przycięcia odpowiedniej gałęzi jesteśmy w stanie wpływać na jakość predykcji.
Budowa modelu klasyfikacyjnego drzewa decyzyjnego
Przejdźmy zatem do tworzenia klasyfikacyjnego drzewa decyzyjnego na piłkarskich danych w celu stworzenia modelu przewidującego wynik końcowy spotkania.
W tej części, przedstawię dwie propozycje modeli drzew decyzyjnych, aby po pierwsze, bardziej przybliżyć tematykę tego rodzaju uczenia maszynowego dla Was, a po drugie w celu znalezienia optymalnego rozwiązania, które moglibyśmy wykorzystać do predykcji.
Zacznijmy od zbioru danych. Tym razem, do analizy wykorzystamy dane pochodzące z Seria A od sezonu 2010 aż do dnia dzisiejszego (tj. 12.10.2018). Nie jest to uzasadnione niczym szczególnym, po prostu, w celu urozmaicenia przeanalizujemy dane dla innej ligi niż, jak dotychczas – hiszpańskiej. Zmienne wykorzystane do modelu, są niemal identyczne jak w zbiorze danych wykorzystanym w poprzednim wpisie. Kilka ostatnich obserwacji zawartych w zbiorze danych przedstawia się następująco :
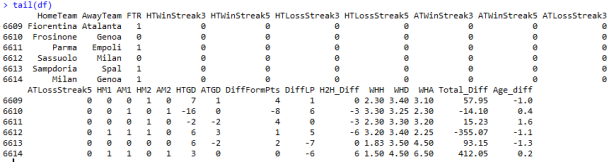
Pierwszy model
Naszą zmienną celu jest zmienna – FTR, która przyjmuje wartość „1” w przypadku wygranej gospodarza lub „0”, w przeciwnym. Następnie, inaczej niż poprzednio dokonano podziału całego zbioru na zbiór treningowy oraz testowy w proporcji 4/1. Wybór obserwacji do każdego z tych zbiorów został dokonany za pomocą losowego wyboru indeksów, wykorzystując przy tym funkcję runif(). Po podziale zbioru na dwie części, stworzony został pierwszy model drzewa decyzyjnego, który w swoim algorytmie wykorzystuje rekursywny podział kolejnych węzłów w drzewie, tak aby miara różnorodności w węzłach spadała. Model uwzględniał wszystkie 22 zmienne objaśniających, tworząc tym samym model pełny. Zmienną objaśnianą bez zmian pozostała zmienna „FTR” przyjmująca dwie kategorie: 1 dla meczów kończących się zwycięstwem drużyny gospodarzy oraz 0 w przeciwnym wypadku. Do stworzenia wspomnianego modelu wykorzystano funkcję rpart() z pakietu rpart w środowisku R. Funkcja ta poza zdefiniowaniem zmiennych oraz wyborem zbioru pozwala na określenie pozostałych parametrów tworzących drzewo decyzyjne. W naszym przypadku potrzebujemy określenia dwóch istotnych parametrów :
- minsplit reprezentującego wartość minimalną, jaką musi stanowić liczba obserwacji, aby dokonany został następny podział, która w naszym przypadku wynosi ,
- oraz cp , czyli kolokwialnie mówiąc – złożoność drzewa decyzyjnego.
Na początku, tworząc pętlę liczącą wartość dokładności modelu dla wartości parametru minsplit od 20 do 350, otrzymamy ramkę danych z wartością dokładności przy danej liczbie parametru minsplit. Na potrzeby stworzenia analizowanych wartości modelu parametr cp został przyjęta na 0.000001.
df_split <- data.frame(minsplit = numeric(), acc = double())
for (i in 20:350){
rpart <- rpart(FTR~., method=”class”, data= train, cp=0.000001, minsplit=i)
t_pred = predict(rpart,test,type=”class”)
confMat <- table(test$FTR,t_pred)
accuracy <- sum(diag(confMat))/sum(confMat)
df_new <- data.frame(minsplit = i, acc = accuracy)
df_split <- rbind(df_split, df_new)}
Wynik działania przedstawiony został na wykresie poniżej.
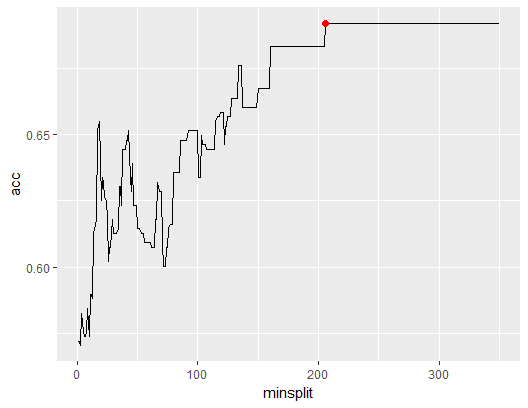
Jak widać, od pewnej wartości parametru minsplit jakość modelu pozostaje na tym samym poziomie ( tutaj 0,6919). Od wartości 206 dla parametr minsplit jakość już się nie poprawia, dlatego taka też wartość została wykorzystana w modelu.
rpart <- rpart(FTR~., method=”class”, data= train, cp=0.00001, minsplit=206)
W wyniku tak dobranego parametru zostało stworzone następujące drzewo decyzyjne:

Interpretacja wyników w przypadku drzewa decyzyjnego jest dużo bardziej intuicyjna aniżeli w przypadku regresji logistycznej. Obserwacje, spełniając odpowiednie warunki związane z daną zmienną, wpadają do kolejnych węzłów. Jedynymi zmiennymi, które uczestniczą w podziale obserwacji na podzbiory w analizowanym przypadku są zmienne: „WHA”, „Total_Diff” oraz „DiffLP”, reprezentujące odpowiednio:
- kurs bukmacherski na drużynę gości (WHA),
- różnica całkowitych budżetów między drużyną gospodarzy a gości w mln (Total_Diff),
- różnica w tabeli w ostatnim sezonie (DiffLP).
Interpretacja drzewa:
- Złożoność drzewa wynosi 5
- Zmienne wykorzystane w modelu : WHA, Total_Diff oraz DiffLP.
- W tzw. korzeniu drzewa następuje podział obserwacji na te z wartością mniejszą niż 3.8 lub większą, równą od 3.8 dla zmiennej „WHA”. Wartość ta dzieli zbiór treningowy na, w przybliżeniu, dwa równe podzbiory (44 i 56%)
- W następnym węźle obserwacje zostają podzielone ponownie według tej samej zmiennej na wartości mniejsze, równe od wartości 7,8 oraz większe równe 7,8.
W tej drugiej grupie znalazło się 316 obserwacji (14 % wszystkich obserwacji ze zbioru treningowego), z czego 79,1% przyjmuje wartość zmiennej objaśnianej równą 1. Oznacza to, że w prawie 80% przypadków drużyna gospodarzy wygrywa spotkanie, jeżeli kurs na drużynę przeciwną wynosi powyżej 7,8. - Obserwacje z wartością zmiennej WHA < 7,8 wpadają do węzła, w którym znajduje się 993 obserwacji ze zbioru testowego, gdzie następuje podział względem zmiennej Total_Diff, na obserwacje mniejsze od wartości 76 oraz większe równe 76.
- Następnie obserwacje dla których wartość, tej zmiennej wynosi powyżej 76 wpadają do liścia, w którym 63% z nich przyjmuje wartość 1 dla zmiennej celu FTR.
- Te obserwacje, dla których różnica w budżetach między drużynami wynosi mniej niż 76 mln, zostają podzielone według zmiennej DiffLP, na te z wartością mniejszą niż -4 oraz większą równą -4 w podziale tym 57 % obserwacji, dla których
DiffLP >= -4 przyjmuje wartość 1 dla zmiennej FTR. - O ile dwa skrajne liście w stworzonym drzewie decyzyjnym przedstawiają dobre i istotne podziały to 3 pozostałe, oscylujące w granicach 50% nie stanowią dobrych predyktorów.
Aby zweryfikować dokładność modelu stworzona została tzw. „macierz trafności”:
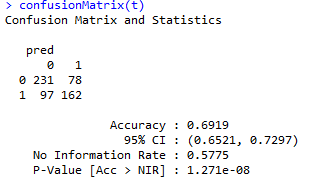
Dla pierwszego modelu dokładność wyniosła ponad 69 %. Na górze przedstawionego output’u przedstawiona została macierz trafności, w której kolumny to wartość przewidywane przez model , natomiast wiersze to wartości rzeczywiste. Przykładowo 231 obserwacji zakwalifikowanych jako wartość „0” zmiennej FTR, rzeczywiście miała tę wartość. Dodatkowo 78 obserwacji zostało zakwalifikowanych jako spotkania w których wygrał gospodarz, natomiast w rzeczywistości mecze te spotkania zostały zakończone wynikiem remisowym lub zwycięskim dla drużyny gości.
Drugi, przycięty model
W algorytmie tym istnieje duże ryzyko przeuczenia drzewa, więc zaleca się, a raczej jest to niezbędne, aby dokonać tzw. „przycięcia” drzewa. Na potrzeby znalezienia optymalnego stopnia złożoności drzewa wygenerowano wykres przedstawiony na poniższym rysunku.

Na podstawie tego wykresu wybrano optymalną wartość złożoności drzewa, tak aby błąd predykcyjny odmierzony na osi pionowej był jak najmniejszy. Optymalna wielkość drzewa, przy której błąd jest najmniejszy, wynosi tylko 2 (górna oś wykresu). Złożoność drzewa jest rozumiana jako liczba liści lub też jako parametr cp (tzw. parametr złożoności), odmierzony na osi poziomej poniżej wykresu. Przed minimalną wartością błędu błąd rósł z racji faktu niedouczenia modelu, natomiast za tym punktem błąd rósł z powodu przeuczenia drzewa klasyfikacyjnego. W wyniku powyższych działań otrzymana została optymalna złożoności drzewa. Na tej podstawie drzewo decyzyjne zostało przycięte za pomocą funkcji prune(), a wynikiem tego działania jest poniższy schemat.

Jak się zatem okazuje, po przycięciu drzewa do optymalnej wartości złożenia otrzymujemy schemat, który wykorzystuje tylko i wyłącznie jedną zmienną. Na jej podstawie dokonany zostaje podział obserwacji na te wygrane przez gospodarzy lub w których gospodarz nie odnosi zwycięstwa.
- 31% obserwacji, dla których wartość zmiennej WHA wynosi poniżej 3,8 przyjmuje wartość 0 dla zmiennej FTR,
- 64% obserwacji dla których wartość zmiennej WHA jest większa lub równa 3,8 przyjmuje natomiast wartość 1 dla zmiennej celu – FTR.
Już na pierwszy rzut oka jesteśmy stanie stwierdzić, że dokładność przyciętego drzewa okazuje się mniejsze niżeli w przypadku wcześniejszym. Potwierdza to output’u z macierzą trafności dla modelu drzewa przyciętego.
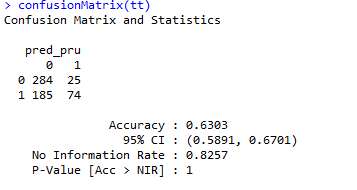
Dokładność w tym przypadku wyniosła 63%, czyli zdecydowanie mniej.
Weryfikacja najlepszego modelu
Najlepszym z dwóch stworzonych modelu okazał się pierwszy z modeli. Dokładność tego modelu wynosi ponad 69%. Tak jak poprzednio, przy weryfikacji modelu regresji logistycznej dokonane zostanie sprawdzenie modelu na danych z ostatniej kolejki, w tym przypadku, ligi włoskiej. Z racji tego, że dane dotyczące najbliższej kolejki aktualizowane są na stronie http://www.football-data.co.uk/ dzień przed pierwszym meczem, weryfikacja zostanie dokonana własnie na ostatnich meczach, czyli w naszym przypadku 8. kolejka Seria A.
| Kolumna1 | HomeTeam | AwayTeam | WHH | WHA | Total_Diff | prediction |
| 1 | Torino | Frosinone | 1,4 | 8,5 | 114,55 | 1 |
| 2 | Cagliari | Bologna | 2,05 | 3,9 | 32,43 | 1 |
| 3 | Empoli | Roma | 5 | 1,67 | -330,9 | 0 |
| 4 | Udinese | Juventus | 8,5 | 1,38 | -665,65 | 0 |
| 5 | Atalanta | Sampdoria | 1,65 | 5,25 | 13,65 | 1 |
| 6 | Genoa | Parma | 1,83 | 4,33 | 10,32 | 0 |
| 7 | Lazio | Fiorentina | 1,8 | 4,33 | 117,65 | 1 |
| 8 | Milan | Chievo | 1,29 | 11 | 433,1 | 1 |
| 9 | Napoli | Sassuolo | 1,36 | 8 | 368,57 | 1 |
| 10 | Spal | Inter | 5,8 | 1,67 | -493,55 | 0 |
Przypomnę, że w kolumnie prediction, znajdują się przewidywane wartości zmiennej FTR, która przyjmuje wartość 1 dla meczów zakończonych zwycięstwem gospodarzy oraz 0 w przeciwnym wypadku.
Jak wyszło ? Zaskakująco dobrze!
Wyłącznie mecz Atlanta-Sampdoria został przewidziany błędnie, co daje skuteczność na poziomie 90% dla danej kolejki.
Aby sprawdzić jak model poradzi sobie z następną kolejką poczekamy jeszcze 4 dni, po których zaktualizuje ten wpis o nowe przewidywane wyniki na najbliższą kolejkę.
Cały kod oraz pliki potrzebne do analizy znajdziecie na moim github repozytorium :
https://github.com/szydlinho/Machine-Learning-to-predict-football-outcome

Klasa! Będę tutaj wpadał – sam uwielbiam piłkę i nie ukrywam, chciałbym się nauczyć analizy danych. Polecam blog http://green-all-over.blogspot.com/, autor jest chyba statystykiem, operuje na o wiele prostszych metodach, niemniej warto poczytać.
Pozdro!
PolubieniePolubienie
Bardzo mi miło i dziękuje za komentarz!
Jeżeli chcesz być na bieżąco zachęcam do polajkowania strony na Facebook’u. Oczywiście, sprawdzę również Twoje polecenie!
Pozdro 🙂
PolubieniePolubienie
Bardzo fajnie się czytało, gratuluję trafionych predykcj! Można coś poobstawiać nawet bazując na nich 😀
Sam jestem pasjonatem piłki nożnej i podejścia analitycznego – w przypadku piłki nożnej właśnie, jest tu spore pole do popisu, dlatego zamierzam śledzić Twoje wpisy. 🙂
W jaki sposób uczyłeś się ML i tych wszystkim tematów związanych z analizą? Sam od jakiegoś chcę zgłębić temat, ale jakoś nie wiem od której strony się za to zabrać…
PolubieniePolubienie
Super, dzięki za komentarz! Takie wiadomości budują, naprawdę 🙂
Jeżeli chodzi o Machine Learning to można powiedzieć, że już jakiś czas temu zainteresowałem się ta tematyką sam. Szukałem materiałów w internecie, których znalazłem mnóstwo! Potem poukładałem sobie to wszystko bardziej w szkole (kończę własnie Analizę Danych na studiach magisterskich). W między czasie oczywiście pogłębiałem swoją wiedzę poprzez samokształcenie. Przeczytałem sporo książek, artykułów dokumentów ogólnodostępnych, jest tego naprawdę sporo. Naturalnym było dla mnie analizowanie piłkarskich danych bo własnie to mnie w tamtym czasie najbardziej nakręcało. A zakres wiedzy jaką znajdziemy w internecie jest praktycznie nieograniczony..
Jeżeli będziesz chciał dowiedzieć się szczegółów dotyczących książek, dokumentów, daj znać, chętnie się podzielę tytułami 🙂
PolubieniePolubienie
Nie ma sprawy! Przeczytałem wszystkie wpisy i trzymają poziom, mega ciekawe rzeczy 🙂 Czasami się trafi jakaś literówka albo przecinek w złym miejscu, ale to szczegóły 😀
Chętnie poznam źródła, z których korzystałeś podczas nauki, więc jakbyś znalazł chwilę i zechciał się nimi podzielić, to byłbym bardzo wdzięczny! Może w końcu mnie to zmotywuje do tego, by zabrać się za to porządnie 🙂
PolubieniePolubienie