
Tematem przewodnim dzisiejszego wpisu, który jest kolejną częścią materiału z przypomnienia statystyki będzie istotność statystyczna oraz p-value. Jako że jest to już druga część serii warto byłoby abyś przed zapoznaniem się z poniższym tekstem powtórzył/a zawartość pierwszej części z „Powtórka ze statystyki”, którą znajdziecie tutaj. Jest to w sumie o tyle istotne, że teksty te w pewnym stopniu się uzupełniają i łatwiej będzie „połączyć kropki”. Bez zbędnego przedłużania wstępu przejdźmy zatem do sedna sprawy 🙂
Jednym z najistotniejszych zadań stawianych przed analitykiem/badaczem, który prowadzi działania badawcze na danych, jest przeniesienie wyników otrzymanych na próbce danych na całą populację. Kryje się za tym problem istotności wyników otrzymanych na próbce. Innymi słowy należy zadać sobie pytanie skąd wiemy, że otrzymane miary na próbce nadają się do generalizacji dla całej populacji.

Trzy najczęściej wykorzystywane narzędzia przez badaczy do poradzenia sobie z tym problemem to:
- testy istotności statystycznej (ang. testing for statistical significance),
- oszacowanie wielkości efektu (ang. effect sizes) oraz
- przedziały ufności (ang. confidence intervals).
Tymi aspektami zajmiemy się własnie w tej części serii.
Wszystkie z tych miar pozwalają określić istotność wyników dokonanej analizy statystycznej. Zanim jednak przejdziemy do opisu każdego z tych narzędzi – przyjrzymy się fundamentalnemu podziałowi statystyki.
Statystyka opisowa jak sama nazwa wskazuje opisuje pewne cechy danego zbiór danych.
Do najczęściej wykorzystywanych miar w statystycy opisowej zalicza się średnią arytmetyczną, zakres danych, medianę, modę, wariancję, odchylenie standardowe, kwantyle itd.). Należy tu zaznaczyć, że otrzymane miary nie mówią nic więcej poza tym co dzieje się poza opisywanym zbiorem danych, nie wykraczają poza niego. Nie istnieje tu zatem zjawisko generalizacji.
Inaczej sprawa się ma właśnie z wnioskowanie statystycznym. Tu właśnie w szczególności chodzi o wykorzystanie otrzymanych wyników wykraczając poza próbką danych na której oszacowywane były dane statystyki. W pewnych przypadkach chcielibyśmy wiedzieć, czy dane wyniki moglibyśmy wykorzystać do opisu populacji. Czyli ciągle kręcimy się wokół tematu generalizacji. Innymi słowy potrzebujemy pewnej miary, która pozwoli nam określić (podjąć decyzję) czy możemy generalizować wyniki czy też nie.
Czemu zatem mierzyć się z tym problemem, nie lepiej po prostu przebadać całą populację? Otóż nie jest to takie proste. Przede wszystkim dlatego, że jest to zbyt czasochłonne i zbyt drogie, ponadto często jest to wręcz niewykonalne.
Podsumowując więc tę kwestię, istotą wnioskowania statystycznego jest przeniesienie wyników otrzymanych na próbce na cała populację.
Istotność statystyczna
Przejdźmy zatem do istotności statystycznej. Zacznę od tego, abyśmy utożsamiali istotność statystyczną z wartością prawdopodobieństwa p. Istotność statystyczna mówi nam o wiarygodności lub prawdopodobieństwie, że estymatory otrzymane z próbki danych reprezentują jakieś „oryginalne” zjawisko (fenomen) w populacji. Innymi słowy, jest to miara, wykorzystywana przez statystyków, która pozwala określić czy w wyniku eksperymentu otrzymaliśmy wyniki bardziej ekstremalne (skrajne) aniżeli wynikałoby to z samego przypadku. Jeżeli wynik leży poza zakresem wariancji przypadku, mówimy, ze jest istotny statystycznie. Pozwala zatem określić czy otrzymane miary na próbce można również wykorzystać na populacji.
Cytując materiał ze strony:
Istotność statystyczna wyniku to prawdopodobieństwo, że zaobserwowane związki (np. pomiędzy zmiennymi) lub różnice (np. pomiędzy średnimi) w próbce pojawiły się czysto przypadkowo (są „dziełem przypadku”) przy założeniu, że w populacji z której próbka została wylosowana powyższe związki lub różnice nie istnieją
Mówiąc o istotności statystycznej musimy zrozumieć, z jakich najważniejszych trzech elementów jest ona złożona. Elementy składowe przedstawione został na schemacie poniżej.

Wykorzystując tekst przedstawiony na Towards Data Science chciałbym odnieść się do każdego z elementu, aby nakreślić każdy jego udział w istotności statystycznej.
- Testowanie hipotez – bardzo szeroki temat, który odnosi się do sprawdzenia przekonań badacza odnośnie danych. Najczęściej stosujemy tę technikę do porównania wyników otrzymanych na próbie z całą populacją lub między grupami w celu określenia ich istotności różnic. Można powiedzieć, że jest to formalny, matematyczny zapis hipotezy. Innym słowy wykorzystujemy testowanie hipotez kiedy chcemy sprawdzić wystąpienie pewnego zjawiska, które nas interesuje. W dalszej części przedstawię przykład, który mam nadzieję, rozwieje wątpliwości.
- Rozkład (normalny) – wspomniany już we wcześniejszym wpisie będzie konieczny do z wizualizowania istotności statystycznej na wykresie. Niekoniecznie zawsze musi to być rozkład normalny, przy testowaniu hipotez i oszacowywaniu p value możemy wykorzystywać różne rodzaje rozkładów, np rozkład t-Studenta. Jest to o tyle niezbędne, że przy testowaniu hipotez musimy założyć rozkład statystyki testowej. Wykorzystujemy rozkład normalny z racji wystąpienia Centralnego twierdzenia granicznego, który przedstawiłem we wspomnianym wyżej wpisie.
- p value – jako wartość prawdopodobieństwa otrzymania wyniki co najmniej tak skrajnego gdyby hipoteza zerowa była prawdziwa.
Żeby to wszystko skleić w całość przejdźmy do przykładu 🙂
Przykład 1
Przeanalizujemy średnią liczbę goli w meczu Premier League w sezonie 18/19 oraz 10/11 w celu sprawdzenia czy wartości tych statystyk różnią się od siebie w sposób istotny statystycznie. Innymi słowy, chcielibyśmy dowiedzieć się czy średnia liczba bramek w meczu znaczącą zmieniła się na przestrzeni niespełna 10 lat. Przypadek ten jest o tyle prosty, że wystarczyłoby porównać ze sobą obie średnie dla każdej z populacji (w tym przypadku wszystkie mecze w danym sezonie w PL) i je porównać. My jednak skomplikujemy sprawę, aby zastosować test hipotezy, i założymy,że nie mamy dostępu do wszystkich meczów z danego sezonu. Dlatego też wylosujemy 25 meczów z sezonu 18/19, obliczymy średnią i porównamy z tą z sezonu 10/11.
Średnia liczba goli w meczu w sezonie 2010/2011 w Premier League wynosiła 2.797.
Średnia liczba goli w meczu z próby o wielkości 25 obserwacji w sezonie 2018/2019 wynosiła 3.4. Co przedstawione zostało na outpucie poniżej.
> proba <- sample(df1$Gole, 25, replace = FALSE) > mean(proba) [1] 3.4
Oczywiście, z racji występowania zjawiska błędu z próby istnieje pewna możliwość wylosowania takich meczów w których średnia będzie wynosiła 2.797. Nie jesteśmy zatem w stanie, na podstawie wyłącznie średniej z próby (3.4) wyciągnąć istotnych wniosków dotyczących średniej liczby goli w meczu w sezonie 2018/19. Potrzebujemy zatem wykorzystać test hipotezy do określenia prawdopodobieństwa otrzymania naszej średniej z próby kiedy średnia dla populacji wynosi 2.797.
- Hipoteza zerowa: Średnia dla populacji (sezon 18/19) równa się średniej z hipotez zerowej (2.797)
- Hipoteza alternatywna: Średnia dla populacji (sezon 18/19) nie równa się średniej z hipotez zerowej (2.797)
OK teraz to gry wchodzi przyrównanie rozkładu z próby do rozkładu np. normalnego lub t-Studenta. Tym razem wykorzystamy rozkład t-Studenta z racji na ilość obserwacji w próbie. Sprawa przedstawia się następująco:
Przed analizą należałoby podkreślić, że przedstawiony rozkład t-Studenta jest przesunięty względem standardowego w celu dopasowania go do danych. Gdybyśmy standaryzowali wartości zmiennej „Gole” do wartości z-score otrzymalibyśmy te sam wykres jednak z punktem centralnym w x=0. Generalnie jest to o tyle istotne, że działając na wartościach znormalizowanych jesteśmy w stanie odczytywać wartość p-value z tablic statystycznych.
Z wykresu nasuwa się wniosek, że najbardziej prawdopodobne wyniki oscylują w granicach średniej z całej populacji dla sezonu 2010/11, co nie powinno dziwić. Możemy odczytać prawdopodobieństwo otrzymania wyniku 3.4. Wynik ten dla obecnego sezonu otrzymany z próby złożonej z 25 obserwacji wygląda dosyć prawdopodobnie. Czy jednak możemy odrzucić hipotezę, że średnia dla populacji dla sezonu 18/19 nie równa się tej dla sezony 10/11 (2.797)? Takie działanie nazywałoby się odrzuceniem hipotezy zerowej, która mówi o równości średnich tych dwóch populacji. Innymi słowy czy różnica miedzy 2.797 otrzymaną na populacji i 3.4 otrzymaną z próby różnią się od siebie w sposób istotny statystycznie? Aby odpowiedzieć na te pytania musimy określić miarę, która będzie determinowała przyjęcie odpowiedniego stanowiska. Będziemy potrzebować poziomu istotności (alfa).
Poziom istotności (określany przed dokonaniem badania!) określa jak silnie wyniki na próbce danych muszą zaprzeczać hipotezę zerową przed możliwości a odrzucenia jej dla całej populacji. Innymi słowy to granica, jak daleko mogą odbiegać wyniki z próby żebyśmy mogli ja odrzucić lub abyśmy nie mieli podstaw do jej odrzucenia. Mniejszy poziom ufności wymaga silniejszego odchylenia statystyki na próbce abyśmy mogli odrzucić hipotezę zerową.
Na wykresie poniżej zaznaczyłem przedział ufności na poziomie alfa = 0.05, co w przypadku dwustronnego testowania hipotezy daje czarne obszary zaznaczone na wykresie.

Każdy z obszarów reprezentuje prawdopodobieństwo równe 0.025, co po zsumowaniu daje zakładane wyżej 5%. Obszary te nazywane są obszarami krytycznymi dla dwustronnej hipotezy testowej. Obszary te reprezentują wartości próbki, które są wystarczająco nieprawdopodobne aby odrzucić hipotezę zerową. Jeśli hipoteza zerowa jest prawdziwa oraz średnia z populacji wynosi 2.797, to 5% ze wszystkich średnich z prób o wielkości 25 wpada w ten obszar krytyczny. Jako, że nasz wynik (3.4) nie wpadł w obszar krytyczny nie mamy podstaw do odrzucenia hipotezy zerowej. Potrzebowalibyśmy zatem wartości znacznie bardzie ekstremalnej (skrajnej) aby móc odrzucić hipotezę zerową.
OK przejdźmy teraz do p-value, które odmierzone zostało na osi y. P-value jest to prawdopodobieństwo, że próba będzie miała co najmniej tak skrajny wynik jak statystyka z analizowanej próby przy założeniu, że hipoteza zerowa jest prawdziwa.

Obszar zaznaczony na wykresie reprezentuje prawdopodobieństwo otrzymania wyniku średniej z próby co najmniej tak skrajnego (zarówno w jedną jak i drugą stronę) jak nasza średnia z nowej próby (3.4). Na osi x odmierzone zostało odchylenie od średniej w populacji (2.797) o różnicę 0.603 (0.603 = 3.4-2.797) w lewo i prawo (2.797 +/- 0.603). Trzeba przyznać, że obszar jest bardzo znaczący, bo wynosi około 66% całego obszaru pod wykresem. Takie zatem jest zaobserwowanie średniej z próby co najmniej tak skrajnego (ekstremalnego) jak wartość średniej z próby w hipotezie zerowej jednocześnie zakładając jej prawdziwość. Słowo ekstremalne i skrajne mogą być nieco mylące, gdyż nasza wartość średnie wcale nie jest „ekstremalna” czy „skrajna”.
Całkowite zacienione pole wynosi 0.66. Jeśli wartość średniej z H0 (hipotezy zerowej) jest prawdziwa i wylosujesz wiele losowych próbek, możesz się spodziewać, że 66% z nich znajdzie się w obszarze przedstawionym na wykresie. To w naszym przypadku jest p-value.
Jeśli p-value jest mniejsze lub równe założonemu wcześniej poziomowi istotności, odrzuca się hipotezę zerową. W naszym przypadku nie mamy podstaw do odrzucenia hipotezy zerowej mówiącej o równości analizowanych średnich.
Rola błędu standardowego w istotności statystycznej
OK, przeanalizujemy na szybko jeszcze jeden przykład, ale zabierzemy się za niego od innej strony.
Kluczem do istotności statystycznej staje się prawdopodobieństwo, ponieważ przy jej określeniu polegamy właśnie na nim aby podjąć ostateczną decyzję. Przy wnioskowaniu statystycznym otrzymujemy statystyki, które otrzymane zostały na podstawie próby losowej (losowego wybrania obserwacji) z populacji.
Intuicyjne jest zatem iż otrzymamy zazwyczaj różne wyniki (estymatory) dla różnych tak samo licznych próbek z tej samej populacji. Z racji tego natomiast, że rozkład statystyki z próby (ang. sampling distributions) posiada pewne stałe własności matematyczne, będziemy mogli na jego podstawie wykorzystać miarę błędu standardowego do oszacowania dokładnego prawdopodobieństwa otrzymania konkretnego estymatora z danej próby, wykorzystując znany lub hipotetyczny parametr całej populacji.
Przykład 2
Przypuśćmy, że znam średnią liczbę goli w meczu dla wszystkich meczów w Anglii od sezonu 2010/11 do dziś (tj. do końca sezonu 2018/19), która wynosi 2.748.
Przyjmijmy również, że wszystkie te mecze stanowią cała populację w badanym problemie. Jako, że średnia jest obliczona dla całej populacji jest to więc parametr a nie estymator, który otrzymalibyśmy z próby. załóżmy, że wybieram losowo 100 meczów
i liczymy dla nich średnią, która wynosi 2.25, z odchyleniem standardowym 1.5.
> proba100 <- sample(gole$Gole, 100, FALSE) > mean(proba100) [1] 2.25 > sd(proba100) [1] 1.5
Średnia ta jest teraz estymatorem ponieważ pochodzi z próbki, nie z całej populacji.
Teraz możemy zadać sobie dwa pytania natury statystycznej:
- Po pierwsze, jeżeli średnia dla naszej populacji wynosi 2.748, a dla próbki 2.25, jakie jest prawdopodobieństwo wybrania losowej próby złożonej ze 100 meczów w których średnia goli na mecz wynosi 2.25?
- Po drugie czy różnica miedzy wynikiem dla całej populacji oraz dla próbki jest statystycznie znacząca?
Tak naprawdę odpowiedz na drugie pytanie oparte będzie na podstawie odpowiedzi do pytania nr 1.
Należy tu podkreślić istotę losowego wyboru obserwacji do próby. Gdybyśmy losowali je w jakikolwiek inny sposób, z łatwością moglibyśmy wybrać taką próbę dla której średnia będzie wynosić właśnie 2.25. Dlatego mówimy tu o losowym wyborze. Jeżeli jednak losujemy dane z populacji, mamy wyłącznie pewne prawdopodobieństwo lub szansę wylosowania próby z daną średnia.
Wracając do przykładu:
Błąd standardowy obliczamy poprzez podzielenie odchylenia standardowego przez pierwiastek z liczby obserwacji w próbie.
Błąd standardowy dla podanego problemy wynosi: Sx = 1.5/sqrt(100) = 0.15
Na podstawie błędu stand. mogę oszacować t-value aby znaleźć przybliżone prawdopodobieństwo otrzymania średniej z próby równej 2.25 w wyniku wyboru losowego, podczas gdy średnia dla populacji wynosi 2.748.
Dla prób liczniejszych niż 120 obserwacji rozkład t Studenta jest identyczny jak rozkład normalny. Dlatego też dla liczniejszych prób statystyka t-Studenta oraz wartość statystyki z oraz ich odpowiednie prawdopodobieństwa są również identyczne
t = ( 2.748-2.25)/0.15 = 3.32
Kiedy już oszacowaliśmy wartość t, możemy z odpowiedniej tablicy statystycznej odczytać prawdopodobieństwo otrzymania wartości t = 3.32 przy danej wartości stopni swobody, czyli w naszym przypadku liczby obserwacji w próbie (100-1). Wartość krytyczna dla założonego poziomu istotności 0.01, przy 99 stopniach swobody odczytana z tablicy rozkładu t studenta wynosi tylko 2,8707 a nasza otrzymana wartość t=3.32. Odczytaliśmy wartość z kolumny 0.005 gdyż z analizowaliśmy problem dwustronnie, czyli poziom istotności 0.01 dzielimy na 2. Możemy zatem powiedzieć (wywnioskować), że wylosowanie próby ze średnią 2.25 podczas gdy średnia dla populacji wynosi 2.748 wynosi mniej niż 0.01. Dlaczego? Przyjrzymy się wykresowi.
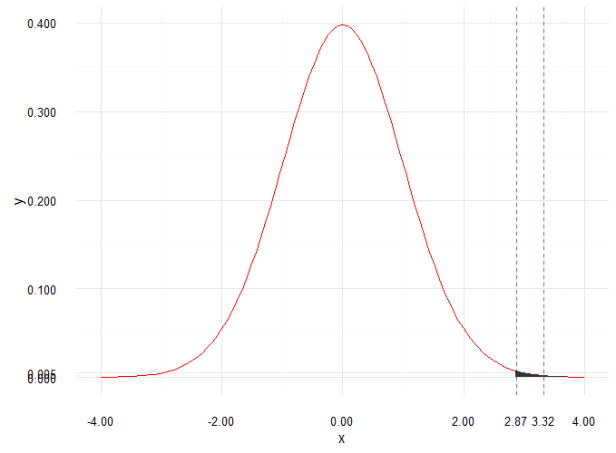
Innymi słowy, szansa wylosowania właśnie takiej próby jest mniejsza niż 1 do 100. Gdybyśmy jednak przyjęli bardziej restrykcyjny poziom ufności okazałoby się, że nasza wartość t znajdowałaby się „przed” obszarem krytycznym. Czyli byłoby większe niż 0.001.
A zatem znamy już prawdopodobieństwo otrzymana danej średniej z próby, która złożona jest z obserwacji wybranych losowo z populacji o znanej średniej. Prawdopodobieństwo jest dosyć małe, jednak wciąż nie-niemożliwe. W naszym przypadku p<.01, które często prezentowane jest w raportach badawczych. Na tej podstawie możemy powiedzieć, że różnica miedzy średnia z populacji – 2.5 oraz z próby = 2.9 – TAK – jest istotna statystycznie na poziomie ufności równym 0.01.
OK! Mamy więc ogólny pogląd na sytuacje związaną z istotności statystyczną.
Cały koncept jest dosyć intuicyjny. Należy podkreślić jednak, że przed oszacowaniem odpowiednich statystyk musieliśmy przyjąć pewne założenia, takie jak np. poziom istotności oraz sformułowanie hipotez. W naszym przypadku sformułowaliśmy hipotezy oraz założenia, które pozwoliły nam zdeterminować, czy daną hipotezę odrzucimy czy utrzymamy. Podsumowując hipotezy, w większości wypadków, główną hipotezę, którą się formułuje jest hipoteza zerowa H0, która będzie sugerowała, że mamy do czynienia z brakiem efektu lub nieznaczącą różnicą. Przykładowo, tak jak w przykładzie powyżej, H0 zakładała, że średnia wyliczona na próbie nie różni się od tej wyliczonej na populacji. Postać hipotezy jest tworzona przed (a priori) dokonaniem testów na istotność statystyczną. Jest to bardzo ważne! Alternatywną hipotezą dla podanej wyżej, jest to że średnie dla populacji i wylosowanej próby różnią się od siebie w sposób istotny statystycznie. Hipoteza alternatywna może przyjmować rożne postacie. Możemy chociażby zaproponować hipotezę alternatywną taką, że średnia z wylosowanej próby jest większa niż populacji.
Pojawiło się tu stwierdzenie różnorodności średnich miedzy sobą. Przyjrzyjmy się bardziej temu zagadnieniu. Jeżeli średnia w populacji wynosi 2.5 , natomiast obliczona średnia na wylosowanej probie jet równa 2.50001, to technicznie średnie te są rożne od siebie. Zastanówmy się jednak czy różnica jest znacząca pod względem statystycznym. Zawsze przecież mamy szanse na wylosowanie takiej próby w której średnia będzie nieznacznie różniła się od tej z populacji. Tym samym prawie niemożliwe staje się wylosowanie takiej próby w której średnia będzie równa tej z populacji, szczególnie kiedy populacja jest duża. Idąc tym tropem należy zastanowić się jaka różnica stanowi ten próg istotnej różnicy miedzy wartościami. W tym miejscu do gry wchodzi poziom ufności (alpha level) lub błąd pierwszego rodzaju.
Jeżeli mówimy o „prawdopodobieństwu”, co jest pewnym skrótem myślowym, tak naprawdę mamy na myśli prawdopodobieństwo otrzymania danego estymatora z uwzględnieniem błędu losowego. Innymi słowy nie powinniśmy się spodziewać dokładnego wyniku z powodu błędu losowego otrzymanego podczas losowego wyboru próby.
Zanim jednak odrzucimy hipotezę zerową, musimy się przekonać, że różnica pomiędzy estymatorem otrzymanym z próby a parametrem z populacji nie wystąpiła wyłącznie z powodu błędu losowego. Powszechne używaną wartością dla wartości determinującej jest poziom 0.05. Innymi słowy, badacze zdecydowali, że jeżeli prawdopodobieństwo otrzymania różnicy pomiędzy estymatorem a parametrem jest mniejsza niż 5% możemy odrzucić hipotezę zerową na rzecz hipotezy alternatywnej, że różnica miedzy nimi nie jest spowodowana błędem losowym. Generalnie, głównym celem klasycznego testowania za pomocą hipotezy jest odpowiedź na pytanie: „Jaki jest prawdopodobieństwo, że w danej próbce danych zaobserwowano jakiś efekt w sposób przypadkowy, losowy?”.
Podsumowując, przy wnioskowaniu statystycznym, naszym głównym celem ma być sprawdzenie, czy coś zaobserwowane w próbce danych reprezentuje rzeczywiste zjawisko w całej populacji. W tym celu tworzymy hipotezę zerową, która mówi o tym że nie ma znaczącej różnicy miedzy estymatorem otrzymanym z próby a parametrem całej populacji. Wybieramy poziom ufności (alfa), które będzie punktem granicznym dla determinowania naszej decyzji, czy odrzucić czy nie mamy podstaw do odrzucenia hipotezy zerowej. Jeżeli otrzymane p-value (które oszacowujemy po obliczeniu konkretnych statystyk dla próby i populacji), jest mniejsze niż nasze alfa, możemy odrzucić hipotezę zerową. Kiedy ją odrzucamy, uznajemy, że różnica miedzy estymatorem a parametrem jest prawdopodobnie nie spowodowana błędem wybory próby losowej. Zawsze istnieje jednak, odrzucając H0 istnieje szansa na to, że doszliśmy do nieprawidłowego wniosku, natrafiając na błąd typu I.
W celu określenia czy dany estymator jest istotny statystycznie dokonujemy kolejnych etapów wnioskowania statystycznego, niezależnie od rodzaju estymatora (czy to jest z-score, t-value, F-value, współczynnik korelacji itd). Po pierwsze szukamy różnicy miedzy estymatorem próby a parametrem populacji (lub jeśli nie jest znany parametr populacji o przyjmujemy hipotetyczną wartość parametru). Następnie dzielimy różnice przez błąd standardowy. Na koniec, określamy prawdopodobieństwo otrzymania różnicy z powodu losowego wyboru próby. Wielkość próby w tym procesie odgrywa znaczącą rolę. W momencie, kiedy włączamy błąd standardowy do wzoru na wartość t, f-value oraz z-score, zauważymy, że im mniejsza wartość błędu standardowego tym większe wartości przyjmują wspomniane statystyki a tym samym stają się bardziej prawdopodobne, że będą statystycznie istotne. Z powodu tego efektu wielkości, czasami zauważymy, że małe różnice miedzy estymatorem próby a parametrem populacji mogą być statystycznie istotne jeżeli próba jest duża. Istnieją różne metody pomiaru efektu wielkości, które zagłębić możecie chociażby tutaj.
Poza p-value oraz wartością wielkości efektu, bardzo ważnym wskaźnikiem przy badania istotności statystycznej są przedziały ufności. Wykorzystuje się je powszechnie w badaniach, kiedy to nie znamy odpowiedniego parametru dla populacji, co jest zjawiskiem powszechnym. Za pomocą prawdopodobieństwa oraz przedziałów ufności możemy wywnioskować parametry dla populacji. Aby przestawić działanie przedziału ufności, zmodyfikujemy nieco zagadnienie naszego problemu z golami. Tym razem, ZAKŁADAMY, że średnia liczba goli we wszystkich analizowanych meczach wynosi 2.748. Techniczne jest to znacznie bliższe prawdy. Obliczony wcześniej błąd standardowy dla analizowanego problemu wynosił 0.15. Za pomocą tych wartości możemy odczytać poziomy ufności. Poziom ufności jest to zakres wartości w których jesteśmy pewni, że przy danym poziomie ufności, zawiera się parametr populacji (np. średnia dla całej populacji). W większości przypadków badacze chcą być pewnie w 95% lub 99%, że przedział ufności zawiera parametr populacji. Podane wartości odnoszą się do p-value odpowiednio 0.05 oraz 0.01. Z racji tego, że przedział ufności zawiera wartości większe i mniejsze niż estymator próby, zawsze będziemy dokonywać testu OBUSTRONNEGO w celu znalezienia wartości t-Studenta.
Jeśli spojrzymy w tablice rozkładu t studenta dla założeń df = 100,
α (alfa) = 0.05 to odczytana wartość t95 = 1.98, co podstawiając do wzoru razem z błędem standardowym daje nam:
- CI95 = 2.25± (1.98)(.15)
- CI95 = 2.25± 0.297
- CI95 = (1.953, 2.547)
Wynik ten oznacza, że przy poziomie ufności 0.95 (α = 0.05) parametr, którym jest średnia populacji mieścić się w zakresie od 1.953 do 2.547. Innymi słowy, znając estymator próby, który wynosi 2.25, a nieznająca parametru populacji, jesteśmy w 95% pewni, że średnia dla populacji, z której wylosowana została próba, mieści się w zakresie 1.953 do 2.547. Zwróćmy zatem uwagę, że nie wcześniej zakładana wartość (średnia dla populacji 2.748) nie mieści się w przedziale otrzymanym przedziale ufności, które wcześniej założyliśmy. Według tego, najbardziej prawdopodobnie jest, że wartość tego parametru nie reprezentuje populacji przy zakładanym poziomie ufności. To dlatego w hipotezie zerowej porównywaliśmy obie wartości i doszliśmy do wnioski, że estymator próby oraz parametr populacji różną się od siebie w sposób istotny statystycznie.
Wyniki nieistotne statystycznie są tak samo ważne i godne opublikowania jak wyniki istotne statystycznie. Wasze badanie nie traci na wartości ponieważ nie udało Wam się zebrać dowodów pozwalających na odrzucenie hipotezy zerowej. Tak samo, jak wasze badanie nie zyskuje na wartości gdy udało Wam się odrzucić hipotezę zerową.
Wartość P mówiącą nam o prawdopodobieństwie możemy zamienić na procenty. Będzie to 84%. Wartość ta mówi nam o tym jak bardzo zebrane przez nas dane wspierają hipotezę zerową. Jak bardzo są jej „zwolennikami”.
Poprawna interpretacja wyniku istotności statystycznej P z punktu widzenia teoretycznego mówi o tym jakie jest prawdopodobieństwo uzyskania takiej różnicy jaką obserwujemy w naszym badaniu lub nawet większej jeśli hipoteza zerowa faktycznie jest prawdziwa.
I tym akcentem możemy zakończyć przeprawę po istotności etatystycznej. Innym razem, w kolejnym wpisie będącym częścią serii „Powtórka ze statystyki” spotkamy się i zapoznamy się bliżej z testami statystycznymi. Dziękuję za uwagę i zachęcam do przedstawiania swojej opinii na temat materiału 🙂
Żródła:
- Statistics Course Pack Set 1 Op: Statistics in Plain English, Fourth Edition (Volume 1) 4th – Timothy C. Urdan
-
Practical Statistics for Data Scientists: 50 Essential Concepts 1st Edition – Peter Bruce
- https://www.statisticshowto.datasciencecentral.com/what-is-statistical-significance/
- https://blog.minitab.com/blog/adventures-in-statistics-2/understanding-hypothesis-tests-significance-levels-alpha-and-p-values-in-statistics
- Wiki
