
Tym wpisem zaczniemy serię artykułów z przypomnienia podstaw statystyki, które są wręcz fundamentalne przy budowaniu modeli uczenia maszynowego. W tej części znajdziecie informacje dotyczące próbki, populacji, rozkładu statystyki z próby, wyborze losowym próby, błędzie standardowym oraz przedziale ufności.

Głównym celem jest chęć stworzenia zwięzłego materiału z którego wyciągniecie lub przypomnicie sobie jak najwięcej, a który jednocześnie będzie stanowił punkt odniesienia do dalszych analiz. Dla mnie samego jest to doskonała powtórka tematu, który pomoże mi w lepszym stopniu realizować kolejne projekty i analizować ich wyniki.
Czemu jednak potrzebujemy zrozumieć statystykę do tworzenia modeli uczenia maszynowego? A dlatego, że uczenie maszynowe wynika ze statystyki i stanowi jego podstawę. Znacznie łatwiej zrozumieć nam statystyki otrzymywane jako wynik działania wbudowanych funkcji uczenia maszynowego. A im lepiej będziemy rozumieć co dzieje się u źródła, tym lepsze i bardziej odpowiednie modele będziemy mogli tworzyć.
Próba i populacja
Próba jest to podzbiór danych z większego zbioru danych, w statystyce ten większy zbiór danych zdefiniowany jest jako populacją.

W statystyce, kiedy mówimy o wyborze próby, należy skupić się raczej na jakości wybranych elementów do niej aniżeli na jej wielkości (ilości obserwacji w próbie), w celu poprawnego wykorzystania jej do estymacji lub tworzenia modelu. Dlatego też, jedną
z cech dobrze wybranej próby danych jest jej reprezentatywność. Próba reprezentatywna to mały podzbiór do którego są wybierane elementy, które odpowiadają kluczowym cechom całej populacji z której jest ona losowana.
Wybór losowy próby jest to proces w którym wszystkie elementy ze zbioru danych tworzących populację mają taką samą szanse na dostanie się do próby w procesie ich losowania. Proces ten może przebiegać ze zwracaniem lub bez zwracania.
Z pojęciem wyboru losowego wiąże się również często zagadnienie błędu systematycznego (obciążenie, ang. bias). Błąd ten jest, jak sama nazwa wskazuje, systematycznie otrzymywany w procesie pomiaru lub wyboru do próby, a który powoduje jednostronne zmiany wyników pomiaru. Należy tu zaznaczyć wyraźną różnicę miedzy błędem otrzymanym w wyniku losowego wyboru próby a błędem systematycznym. Bardzo dobry przykład rozróżnienia dwóch parametrów możemy znaleźć w książce. Obciążenie będzie oznaczało „skierowanie” wyboru obserwacji w odpowiednim kierunku. Jeżeli losowo wybiorę próbę z populacji, mogę się spodziewać, że będzie się ona różniła od innej próby wybranej losowo z tej samej populacji. Mimo wszystko wiem, że pierwsza losowo wybrana próba będzie się różniła od drugiej losowo wybranej próby (jeśli będą tego samego rozmiaru) w sposób losowy, nie systematyczny. Tak więc moje próby nie będą obciążone, jeśli będę wybierał kolejne w taki sam losowy sposób. Jeżeli natomiast, będę ograniczał się przy wyborze do próby wyłącznie do konkretnego obszaru całej populacji – próba będzie obarczona błędem systematycznym. Przykładem takiego obciążenia, może być wybór piłkarzy do analizy wyłącznie z danego kraju (których cechy są podobne), kiedy na celu mamy wyestymowanie parametrów reprezentujących piłkarzy na całym świecie.
Parametr i estymator
Przejdźmy zatem do analizowania konkretnych statystyk z populacji i próby. Symbolem X̄ oznacza się średnią z próby wybranej z populacji, natomiast μ jest to średnia z całej populacji. Takie rozdzielenie parametrów zastosowane jest z racji na to, że statystykę z próby możemy oszacować, natomiast parametr dla populacji często musimy właśnie wywnioskowany ze statystyki otrzymanej na próbie. Warto tutaj zaznaczyć, że własnie dlatego, że często nie posiadamy dokładnej informacji na temat populacji, jesteśmy narażeni na zjawisko błędów systematycznego o którym wspomniałem powyżej. Głównym powodem jego wystąpienia jest zjawisko wyboru próby obarczonego błędem systematycznym. Chodzi tu o to, że wybór obserwacji z populacji do próby odbywa się w sposób selektywny. Działanie takie mogło być zamierzone lub niezamierzone jednak prowadzi ono do nieprawidłowych wniosków na temat populacji. Generalnie więc szukamy parametrów opisujących populacje na podstawie statystyk, które jesteśmy w stanie oszacowań z posiadanej próby.
Rozkład statystyki z próby
Tym samym płynnie możemy przejść do pojęcia rozkładu z próby. Rozkład z próby jest to rozkład częstości wystąpień statystyki z wielu losowych próbek pobranych z danej populacji. Czyli losujemy próbę, liczmy dla niej odpowiedniej statystykę, zapisujemy, losujemy następną próbę, liczymy, zapisujemy, losujemy, liczymy, zapisujemy i tak dalej. Przykładem jest rozkład średniej z próby. Statystyka ta jest powszechna i bardzo istotna dla badaczy, gdyż to na jej podstawie dokonuje się wnioskowania dotyczącego średniej dla całej populacji.
Generalnie, próbki pobierane są z populacji główne w celu pomiaru jakiejś wartości lub stworzenia modelu na nich (np. modelu właśnie uczenia maszynowego). Kiedy dokonujemy zatem estymacji lub stworzenia modelu na podstawie próby, czyli nie dysponujemy wszystkimi obserwacjami z całej populacji, jesteśmy narażeni na błąd. Błąd ten może się różnic pomiędzy rożnymi próbkami pobranymi z tej samej populacji. Naszym głównym celem w tej kwestii jest miara jak bardzo mogą różnić się od siebie te statystyki. Gdybyśmy mieli dostęp do bardzo wielu danych, moglibyśmy wylosować dodatkowe próbki i określić rozkład danej statystyki na ich podstawie. Zazwyczaj jednak nie jest tak kolorowo, gdyż nie mamy często dostępu do wystarczającej ilości danych. W takich przypadkach oszacowujemy estymatory lub tworzymy modele z wykorzystaniem łatwo dostępnej ilości danych, lub takiej, która po prostu posiadamy. Rozkład statystyki z próby takiej jak średnia zazwyczaj jest znacznie bardziej regularny i ma bardziej „zaokrąglony” kształt aniżeli rozkład bezpośrednio z danych. Ponadto, im więcej obserwacji w próbie tym bardziej „spiczasty” ma on kształt a tym samym bardziej dokładniej przedstawia parametr dla populacji. Aby zilustrować przedstawiany tutaj problem załączyłem 3 wykresy poniżej.
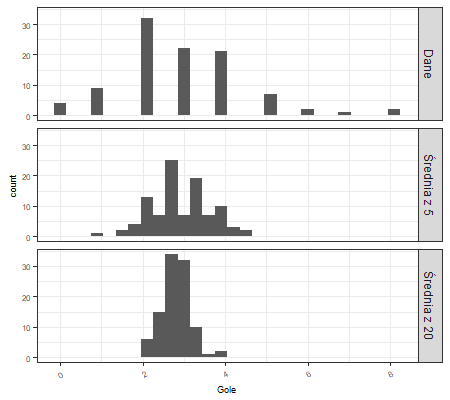
Przeanalizujmy zmienną ilości goli w meczu w Premier League 2019/20. Histogram przedstawiający rozkład z danych (pierwszy od góry) jest bardzo szeroki z prawostronną skośnością w stronę większej liczby ilości goli w meczu. Dwa dolne histogramy przedstawiają histogram dla średnich z 5 wylosowanych wartości (próba o wielkości 5 obserwacji) oraz 20 (próba o wielkości 20 obserwacji). W tym przypadku zastosowałem technikę ze zwracaniem, z racji na stosunkową mała liczbę obserwacji w zbiorze danych. Na przedstawionych wykresach widać wyraźnie jak zmienia się rozkład (w sensie wariancji, zróżnicowania) wartości oraz jak zbiega się wraz ze zwiększeniem liczby obserwacji w próbie do postaci coraz bardziej zcentralizowanej.
Jako bardzo istotne zagadnienie w tym temacie należałoby przedstawić pojęcie Centralnego twierdzenia granicznego. Mówi ono, że przy dostarczeniu wystarczająco licznej próby, rozkład średnich wyliczonych z wielu prób będzie bardzo zbliżony do krzywej rozkładu normalnego, nawet jeśli dane z źródłowej populacji nie posiadają charakterystyki rozkładu normalnego. To założenie jest o tyle istotne, że pozwala na wykorzystanie działań jak na danych z rozkładu normalnego takich jak wykorzystanie rozkładu t-Studenta przy rozkładzie losowym do wnioskowania statystycznego, czyli przedziałów ufności i testów hipotezy. Zwróćmy chociażby uwagę na przykład przedstawiony powyżej. Same zmienne nie były rozłożone normalnie, jednak już statystyki z próby coraz bardziej przypominały jego kształt.
Błąd standardowy
Poza błędem systematycznym kolejnym błędem, który będzie pojawiał się w naszych rozważaniach a jest tym samym mocno związany z rozkładem z próby jest błąd losowy (standardowy). Jest to wartość, która przedstawia zsumowaną zmienność w rozkładzie danego estymatora z próby. Innymi słowy jest to normalne odchylenie rozkładu z próby pewnej statystyki (np. średniej lub korelacji). Jeszcze inaczej można powiedzieć, że błąd standardowy jest to miara losowej wariancji jaką możemy oczekiwać między próbami o tak samo licznych próbach wylosowanych z tej samej populacji.
Błąd standardowy średnich mówi nam jak bardzo pewni powinniśmy być, że średnia z próby reprezentuje rzeczywistą średnią z populacji. Innymi słowy błąd ten zapewnia nam miarę jakiego błędu możemy spodziewać się kiedy mówmy, że średnia z próby reprezentuje średnią z całej populacji. Z tego też powodu nazwy się go standardowym.
Aby go oszacować, należy podzielić odchylenie standardowe próby przez liczbę obserwacji w tej próbie.
Wy estymowany błąd standardowy = SE (ang. standard error) = s/√n,
gdzie s – odchylenie standardowe w próbie, n – liczba obserwacji w próbie.
Dlaczego wyestymowany? A z racji tego, że właściwy błąd standardowy w liczniku ma odchylenie standardowe w populacji, które zazwyczaj nie jest znane. Dlatego, też musimy właśnie estymować jego wartość na podstawie próby. W dalszej części będę posługiwał się w uproszczeniu pojęciem błędu standardowego.
Z przedstawianego wzoru wynika, że wraz ze wzrostem liczby elementów w próbie, błąd standardowy maleje, co mogliśmy zaobserwować na 3 histogramach przedstawianych powyżej.
Aby oszacować błąd standardowy należy:
- Zebrać pewną liczbę nowych próbek z populacji,
- Dla każdej z nich oszacować statystykę (estymator np. średnia)
- Oszacować odchylenie standardowe dla każdej ze statystyk oszacowanych w punkcie 2. – następnie możemy wykorzystać otrzymany wynik jako estymator błędu standardowego.
Bootstrapping
W praktyce, podejście zbierania nowych próbek do estymowania błędu standardowego jest bardzo czasochłonne i często po prostu nieodpowiednie. Badacze natomiast wymyślili lepszy sposób na jego estymację bez losowania nowych próbek. Mowa tu o metodzie Bootstrapping (pol. metody samowsporne), która polega na dodatkowym losowaniu próbek ze zwracaniem bezpośrednio z pobranej wcześniej próbki, a następnie ponownego oszacowanie statystyki lub modelu dla każdej z nich. Próbka bootstrapowa jest zatem próbką, która została wylosowana ponownie z danej próbki danych. Koncepcyjnie, można wyobrazić sobie proces bootstrapowania jako zamienianie oryginalnej próbki danych wielokrotnie (tysiąc czy milion razy) w efekcie czego otrzymamy hipotetyczną populację, która reprezentuje całą zawartą wiedzę w danej próbce danych. Jest po prostu znacznie większa niż próbka.

Następnie możemy losować próbki z hipotetycznej populacji w celach wysetymowania rozkładu z próby. Innymi słowy wyciskamy jak najwięcej z danej próbki danych, która posiadamy. Metoda ta zmusza próbę do udostępnienia wszelkiej informacji jaką ta próba posiada.
W praktyce nie jest konieczne aby powielać próbkę bardzo wiele razy. Po prostu podmieniamy każdą obserwację przy każdym losowaniu, czyli innymi słowy losujemy ze zwracaniem. W taki sposób możemy stworzyć populację z nieskończoną ilością obserwacji w której prawdopodobieństwo wylosowania danego elementu pozostaje niezmienione przez cały proces losowania.
A oto jak przebiega proces bootstrapowania:
- Wybieramy próbkę z populacji o wielkości n,
- Losujemy ze zwracaniem próbkę z oryginalnej próbki danych (pkt. 1) o tej samej wielkości n i powtarzamy ten proces R-razy. Każda z otrzymanych próbek jest nazywana Bootstrap Sample,
- Dla każdej z nich oszacowujemy daną statystykę θ, a zatem otrzymamy R-estymatorów statystyki θ,
- Konstruujemy rozkład z próby na podstawie R estymatorów statystyki θ i wykorzystujemy go do dalszego wnioskowania statystycznego, takiego jak:
- Wyestymowanie błędu standardowego statystyki θ,
- Odczytanie Przedziału Ufności dla statystyki θ.
Zaraz, zaraz ale po co nam tak właściwie bootstrapping?
Generalnie, jak już wspominałem wcześniej, z reguły nie mamy dostępu do danych dla całej populacji i opieramy się wyłącznie na próbce z nich. Dlatego też oszacowujemy parametry populacji wyłącznie poprzez otrzymane estymatory na próbce danych.
W naszym przypadku jeśli mówiliśmy o statystyce, mieliśmy na myśli estymator, czyli statystykę, która daje nam sposób na otrzymanie oszacowania parametru. Jeśli jest to średnia z próby, oznaczamy ja X̄.
Z powodu występowania różnorodności próbkowania, czyli miary jak różnią się estymatory pomiędzy próbkami, nigdy średnia z próby nie będzie równa średniej z całej populacji. Zatem, przedstawiając/raportując nasze oszacowania w badaniach poza samą wartością estymatorów musimy przedstawić dokładność naszych obliczeń. Tą miara jest już wcześniej przedstawiony błąd standardowy. Mówi nam on jak bardzo nasze oszacowania na próbce danych różnią się od rzeczywistego parametru populacji i w jakim zakresie możemy przyjąć go za istotny.
OK, ale co dalej? Wszystko powoli składa się w jedną całość.
Przyjęte jest, że jeżeli estymator jest w rozkładzie normalnym lub zbliżonym do rozkładu normalnego, wtedy możemy spodziewać się, że nasze oszacowania/estymacje będą różniły się mniej niż jedną wartość błędu standardowego w 68% oraz mniej niż dwa błędy standardowe w około 95% wszystkich przypadkach. Dlatego też możemy wykorzystać tę zasadę do naszych rozważań polegając niejako na centralnym twierdzeniu granicznym, który mów nam, że rozkład z próby, niezależnie od tego jaki rozkład mają same dane, jest zbliżony do rozkładu normalnego.
Doszliśmy zatem do momentu, gdzie otrzymaliśmy odpowiedź na pytanie po co wykorzystujemy metody bootsptrapowe. Oszacowanie błędu standardowego estymatora w rzeczywistości jest ciężkie do zrealizowania. W większości, nie posiadamy dokładnego wzoru takiego jak błąd standardowy z próby. W przypadkach, kiedy nie możemy zapewnić wspomnianych wcześniej założeń, lub też nie posiadamy dokładnego wzoru na wysetymwoanie błędu standardowego, właśnie bootstrapping wydaje się być idealny rozwiązaniem, gdyż z jednej próbki jesteśmy w stanie wycisnąć bardzo wiele i wykorzystać to do estymowania parametrów z populacji.
Przedział ufności
Kolejnym zastosowaniem metody bootstrapowej jest otrzymanie w wyniku jej działania przedziałów ufności. Dla danej próbki danych o wielkości n i dla danej statystyki z próby (estymatora), bootstrapowy algorytm do otrzymania przedziału ufności dla tej statystyki jest następujący:
- Wylosuj losową próbę o wielkości n ze zwracaniem z posiadanych danych,
- Zapisz otrzymaną statystykę, która nas interesuje (np. średnia z próby),
- Potwórz kroku w punktach 1. i 2. wiele razy (R-razy),
- Dla przedziału ufności x%, przytnij [1 – [x/100]) / 2]% wylosowanych R-wyników danych dla obu z końców jego rozkładu,
- Otrzymane przycięte końce stanowią x% przedział ufności otrzymany z metody bootstrapowej.
Bootstrapping zatem jest narzędziem, który możemy wykorzystać do wygenerowania przedziału ufności dla większości statystyk lub parametrów modelu. Poza wspomnianym sposobem otrzymywania przedziały ufności możemy otrzymać jego parametry ze wzoru, formuły, w szczególności na podstawie rozkładu t-Studenta (o czym w następnym materiale).
Wartość procentowa, o której wspomniałem przy omawianiu przedziału ufności, jest określana terminem poziom ufności. Im większy, tym szerszy staje się przedział (zakres). Tym samym jesteśmy bardziej pewni, że szukany parametr znajduje się w oszacowanym zakresie. A zatem im mniejsza wartość poziomu ufności tym jesteśmy mniej pewni wystąpienia parametru w tym przedziale.
Podsumowując ten fragment:
- Przedziały ufności zazwyczaj wykorzystywane są do prezentowania estymacji w określonym zakresie (obszarze),
- Im więcej danych posiadasz, tym mniej zmienna będzie estymacja próbki,
- Im przyjmiesz mniejszy poziom ufności, tym węższy będzie przedział ufności,
- Metoda bootstrapping jest efektywnym narzędziem do konstruowania przedziałów ufności.
Na tym zakończymy część pierwszą złożoną na całą serię dotycząca przypomnienia najważniejszych elementów ze statystyki. W następnym materiale prześwietlimy temat istotności statystycznej.
Źródła:
- Statistics Course Pack Set 1 Op: Statistics in Plain English, Fourth Edition (Volume 1) 4th – Timothy C. Urdan
-
Practical Statistics for Data Scientists: 50 Essential Concepts 1st Edition – Peter Bruce
- https://towardsdatascience.com/an-introduction-to-the-bootstrap-method-58bcb51b4d60
- Wikipedia

Jeśli dolączyłbyś przykład łatwiej dałoby się to wszystko przypomnieć…
Choć generalnie – dobra robota.
PolubieniePolubienie