
Jakiś czas temu przedstawiałem na czym polega i jak działa jeden z najbardziej rozpowszechnionych algorytmów uczenia maszynowego – drzewa decyzyjnego. O ile w tamtym materiale zaprezentowane zostały podstawy działania algorytmu, o tyle w tym pokuszę się o rozszerzenie tego zagadnienia. Zajmiemy się tym razem optymalizacją stworzonego modelu, tak aby otrzymać jak najlepszą dokładność. Tym samym będzie to również przewodnik po budowie tego algorytmy w pythonie. Postaramy się tak zmodyfikować tzw. hyperparametry modelu aby jak najlepiej służył do predykcji nowych obserwacji.
Jak działa sam algorytm drzewa decyzyjnego i o co w nim chodzi przedstawiłem we wpisie Model drzewa decyzyjnego do predykcji wyników. Tym razem chciałbym się skupić wyłącznie na jego doszlifowaniu a raczej ulepszeniu jego działania, a w konsekwencji otrzymaniu lepszej skuteczności modelu. Przejdźmy zatem do implementacji modelu. Oczywiście z racji na autentyczność strony wykorzystamy piłkarskie dane, włącznie z aktualnie trwającym sezonem. Dane możecie pobrać tutaj , natomiast sam kod wrzucę już niedługo na swój gtihub.
Przejdźmy zatem do budowy modelu.
Budowa modelu drzewa decyzyjnego
Model budowany jest za pomocą funkcji sklearn.tree.DecisionTreeClassifier() w której mamy do wyboru wiele hyper-parametrów, które będą służyły nam do optymalizacji zbudowanego modelu. Chodzi generalnie o to, żeby tak dobrać parametry aby zbudowany algorytm dokonywał klasyfikacji na danych, które mamy w sposób najbardziej zoptymalizowany. Co w efekcie będzie poprawiało jego moc predykcyjną na przyszłych, nowych danych. Nie będziemy jednak tutaj rozważać wyboru zmiennych do modelu bo jest to temat na oddzielny artykuł. Skupiamy się tu wyłącznie na „atrybutach” drzewa decyzyjnego, które budujemy. Parametry, które będziemy analizować to:
- criterion,
- max_depth,
- min_samples_split,
- min_samples_leaf.
Oczywiście możliwości zmiany domyślnych parametrów jest więcej, wszystkie możecie przeanalizować na stronie dokumentacji przedstawionej powyżej.
Tworząc zwykłe drzewo losowe, bez określenia jakiegokolwiek parametru, czyli pozostawiając je wszystkie jako domyślne otrzymujemy dokładność modelu, sprawdzoną na zbiorze testowym, w okolicach 0.6.
clf = DecisionTreeClassifier(random_state= 101)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
metrics.accuracy_score(y_test, y_pred)Out[47]: 0.6161321671525753Kryterium podziału
Pozwala nam określić jakie kryterium przyjmiemy do określenia jakości podziału danych w węźle. Innymi słowy określamy jak będziemy badać jakoś podziału. Do wyboru mamy dwie opcje:
- ‚gini’ (które jest domyślnym parametrem)
- ‚entropy’.
Pierwszy z nich wykorzystuje Index Gini’ego do określenia jakości podziału, natomiast drugi – parametr zdobycia informacji (ang. information gain). Oba te parametry różnią się od siebie definicją i sposobem wyliczenia ich wartości, czyli innymi słowy inaczej się wylicza ich wartości. W zależnosci od tego jakie kryterium chcemy przyjąć – taki parametr wybierzemy.
Index Giniego dla każdej zmiennej/cechy rozważa podział na dwa podzbiory. Liczony jest on na podstawie klasycznego algorytmu CART, który jest bardzo łatwy do oszacowania. To jak dokładnie wygląda wzór oraz sposób wyliczenia zostało przedstawione w artykułach, które znajdziecie na końcu wpisu (w bibliografii).
Najważniejsze założenia przy wyborze podziału metodą Giniego:
- faworyzuje większe podziały,
- przy jego wyliczeniu wykorzystuje się proporcje klas podniesioną do kwadratu
- idealnie sklasyfikowany podział będzie miał wartość Indeksu Giniego równą zero,
- im mniejsza wartość Indexu Giniego, tym lepszy podział danej zmiennej.
Jeśli chodzi o koncepcję entropii możemy ja rozumieć jako miarę jednorodności (lub określając na opak – „zanieczyszczenia„) w zbiorze wejściowym. Wartość „zdobytą” stanowi spadek entropii w podzielonych zbiorach danych, co jednocześnie oznacza wzrost jednorodność w grupach.
Najważniejsze założenia przy wyborze podziału metodą Entropy:
- faworyzuje podziały z mniejszą ilością obserwacji ale wieloma unikalnymi wartościami,
- przy jego obliczaniu prawdopodobieństwo otrzymania klasy jest ważone logarytmem o podstawie dwa z prawdopodobieństwa wystąpienia tej klasy,
- im mniejsza wartość Entropii tym podział jest lepszy,
- wartość informacji zdobytej jest to różnica entropii węzła wyższego minus entropia węzła znajdującego się pod nim (rodzic – dziecko). Inaczej mówiąc różnica entropii w zbiorze przed podziałem oraz średniej entropii po podziale danych w oparciu o pewną zmienną.
Mamy więc do wyboru pierwszy parametr w funkcji tworzącej algorytm drzewa decyzyjnego – criterion.
Zmodyfikujemy zatem wyłącznie ten parametr funkcji DecisionTreeClassifier(). Aby modele były uczone oraz testowane na tych samych zbiorach określamy parametr random_state na tę samą wartość (np. 101 lub cokolwiek innego, ważne aby były takie same). Efekt jest następujący:
clf = DecisionTreeClassifier(criterion="entropy", random_state= 101)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
metrics.accuracy_score(y_test, y_pred)Out[49]: 0.5957240038872692clf = DecisionTreeClassifier(criterion="gini", random_state= 101)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
metrics.accuracy_score(y_test, y_pred)Out[50]: 0.6161321671525753Okazuje się, że zmiana parametru kryterium podziału na „entropy” pogarsza w naszym przypadku dokładność modelu o około 0.02 jednostki.
Maksymalna głębokość drzewa
W tym przypadku mamy do czynienia z tzw. przycinaniem drzewa. Generalnie, jeśli nie określimy żadnej wartości dla tego parametru, nasze drzewo decyzyjne będzie dokonywało podziałów do momentu aż osiągnie w danym węźle liczbę obserwacji równą parametrowi min_samples_split , który domyślnie wynosi 2. Mówiąc inaczej, nasze drzewo będzie się tak dalece rozwarstwiało aż w liściach końcowych będą znajdowały się jednorodne podzbiory o wielkości min równej 1. Jest to bardzo niekorzystne, szczególnie dla dużych zbiorów złożonych z wielu zmiennych gdyż znacznie wzrasta uszczegółowienie modelu. W konsekwencji model jest wręcz idealnie dopasowany do zbioru treningowego, na którym był tworzony, a co za tym idzie nie jest zdolny do uogólnienia i wykorzystania go na niezależnych zbiorach testowych. Takie zjawisko nazywamy przeuczeniem, a jest to tym samym jeden z poważnych mankamentów modelu drzewa decyzyjnego, który możemy zlikwidować właśnie poprzez przycięcie drzewa.
Aby lepiej zobrazować problem przedstawie dwa drzewa decyzyjne: jedno z domyślnie ustawionymi wartościami parametrów drzewa decyzyjnego oraz drugie z ograniczoną maksymalną głębokością drzewa do wartości 5.

Pierwsze z nich poza tym, że jest kompletnie nieczytelne jest też niemożliwe do uogólnienia. W ekstremalnych wypadkach może dojść do sytuacji, gdzie każda z obserwacji ląduję w jednym liściu co jest kompletnie bezużyteczne. Tworzymy drzewo złożone z tylko i wyłącznie szczególnych przypadków, a przecież mamy stworzyć model, który będziemy mogli wykorzystać do nowych danych! Po to właśnie potrzebna nam jest zdolność modelu do uogólnienia.

Drugi przykład, nie dość, że jest znacznie bardziej czytelny to również bardziej ogólny a w konsekwencji, miara dokładności na niezależnym zbiorze testowym jest wyższa.
Dlaczego jednak to jest takie istotne z punktu widzenia jakości modelu? Poniższy rysunek przedstawia oszacowane dokładności modelu zarówno na zbiorze testowym jak i treningowym. Na osi x przedstawione zostały kolejne wartości parametru maksymalnej głębokości drzewa decyzyjnego, natomiast na osi y – dokładność modelu.
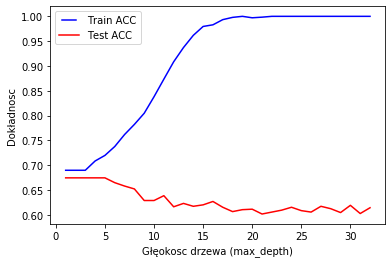
Wraz ze wzrostem złożoności drzewa, model coraz bardziej dostosowuje się do obserwacji zawartych w zbiorze treningowy, o czym świadczy niebieska linia szybująca gdzieś w okolicach dokładności 100%. W takim przypadku dochodzi do wcześniej wspomnianego zjawiska przeuczenia modelu. Wraz ze wzrostem głębokości drzewa, dokładność na zbiorze testowym spada.
Zwróćmy uwagę na wynik prostej pętli przedstawiającą dokładności wyliczone na zbiorze testowym dla różnych wartości parametru max_depth.
for i in range(1,16):
clf = DecisionTreeClassifier(criterion="gini", max_depth=i, random_state= 101)
clf = clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
print("Dokładnosc dla depth = ", i ," wynosi :",round(metrics.accuracy_score(y_test, y_pred), 4))Dokładnosc dla depth = 1 wynosi : 0.6744
Dokładnosc dla depth = 2 wynosi : 0.6744
Dokładnosc dla depth = 3 wynosi : 0.6744
Dokładnosc dla depth = 4 wynosi : 0.6744
Dokładnosc dla depth = 5 wynosi : 0.6744
Dokładnosc dla depth = 6 wynosi : 0.6647
Dokładnosc dla depth = 7 wynosi : 0.6579
Dokładnosc dla depth = 8 wynosi : 0.6443
Dokładnosc dla depth = 9 wynosi : 0.6229
Dokładnosc dla depth = 10 wynosi : 0.6317
Dokładnosc dla depth = 11 wynosi : 0.6395
Dokładnosc dla depth = 12 wynosi : 0.6385
Dokładnosc dla depth = 13 wynosi : 0.6327
Dokładnosc dla depth = 14 wynosi : 0.6142
Dokładnosc dla depth = 15 wynosi : 0.6025Zwiększając model o kolejne głębokości i coraz większe rozgałęzienia, nie otrzymujemy dokładności wyższej co więcej zaczyna ona spadać. Od pewnej głębokości drzewa, model zaczyna coraz bardziej dopasowywać się do zbioru na którym się uczy, a tym samym jego zdolność do klasyfikacji na nowych danych jest coraz mniejsza.
Minimalna liczba obserwacji w węźle lub liściu
O liczbie obserwacji w węźle (czyli przed danym podziałem) wspomniałem powyżej, jednak liczba obserwacji w liściu jest to minimalna liczba podzbiorów wymagana w liściu drzewa decyzyjnego. Zatem każdy kolejny podział w węźle będzie miał miejsce tylko i wyłączenie jeśli stworzy on grupy złożone z liczby obserwacji równej min_samples_leaf zarówno w prawej i lewej gałęzi. Domyślna wartość minimalnej liczebności grupy w liściu równa się 1. Wynika to również z domyślnej wartości minimalnej liczby obserwacji w węźle, która = 2. Domyślnie więc drzewo będzie się rozgałęziało aż do momentu kiedy w każdym z ostatnich węzłów będą 2 obserwacje, a w konsekwencji w każdej z grup końcowych będzie po jednej obserwacji ze zbioru treningowego.
Należy tutaj podkreślić, że zarówno parametr min_samples_split oraz min_samples_leaf będą miały wpływ na przycięcie drzewa w podobnym stopniu jak max_depth. W celu uzasadnienia istotności określania parametru min_samples_split stworzony został wykres przedstawiający dokładność wyliczoną na odpowiednim ze zbiorów modelu.

Wnioski płynące z analizy wykresu są takie same jak przy okazji analizowaniu maksymalnej głębokości drzewa. Proszę zwrócić uwagę, że jeśli określimy parametr min procent zbiory wykorzystany do podziały w każdym węźle na wartościowy > 20%, nasza dokładność modelu się nie poprawi.
Biorąc pod uwagę powyższe zalecenia zmienimy zatem wartość parametru min_samples_split na równą 0.2. Wynik jest następujący:
clf = DecisionTreeClassifier( criterion = "gini", min_samples_split= 0.2, random_state= 101)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
metrics.accuracy_score(y_test, y_pred)Out[12]: 0.6754130223517979Wspomniałem również wcześniej, że niektóre parametry są w pewnym stopniu „wymienne” i do przycięcia drzewa decyzyjnego możemy wykorzystać zarówno parametru max_depth jak i min_samples_split oraz min_samples_leaf . Na dowód tego, zwróćcie proszę uwagę na dokładność tak zbudowanego drzewa:
clf = DecisionTreeClassifier( criterion = "gini", min_samples_split= 0.2, max_depth = 5, random_state= 101)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
metrics.accuracy_score(y_test, y_pred)Out[14]: 0.6754130223517979Nie jest ona zatem lepsza od tego, która otrzymaliśmy wyżej.
Podsumowanie
Tyle zatem mogliśmy wycisnąć z operowania różnymi wartościami hyperparametrów drzewa decyzyjnego. W artykule tym przedstawiłem najważniejsze, choć nie wszystkie możliwości optymalizowania modelu drzewa decyzyjnego. Oczywiście, może się okazać, że dla Waszych danych parametry te będą wyglądać zupełnie inaczej, dlatego też warto sprawdzać jak model klasyfikuje nowe obserwacje uwzględniając dane parametry w jego budowie.
W tekście tym wykorzystałem uproszczony schemat budowania modeli predykcyjnych, gdyż zbiór danych powinniśmy podzielić na 3 części (treningowy, walidacyjny i testowy). Po takim podziale zmiany parametrów w modelu powinniśmy „sprawdzać” na zbiorze walidacyjnym a dopiero po wybraniu najlepszych wartości parametrów – zbadać jego skuteczność na kompletnie niezależnym zbiorze testowym. Tym razem jednak z powodu mniejszego skomplikowania i czytelniejszego działania postanowiłem pominąć ten istotny krok w budowaniu modelu.
Bibliografia
