
Przed opublikowaniem nowego wpisu dotyczącego drzew losowych, chciałbym tym razem bardziej skupić się nad wykorzystywanym zbiorem danych. Wpis ten jest pewną odskocznią od wyznaczonego wcześniej trendu, jednak uważam, że jest bardzo potrzebny. Przede wszystkim dlatego, iż wraz z rozwojem algorytmów, modeli pojawiają się nowe pomysły, które potem okazują się tymi, które poprawijają jakość tworzonej pracy. Zachęcam do zapoznania się z materiałem!
Zmienne wykorzystane we wcześniejszych pracach zostały przedstawione i opisane w rozdziale Przewidywanie wyniku spotkania z wykorzystaniem regresji logistycznej. Jak wynikało z wcześniejszych analiz a w konsekwencji wyników stworzonych modeli, tylko niektóre zmienne zawarte w „surowym” zbiorze danych były brane pod uwagę przy kategoryzowaniu zmiennej celu. Zmienne, które prawie zawsze były wykorzystywane w modelach reprezentowały kursy bukmacherskie oraz bezwzględną różnicę budżetów dwóch klubów, które rozgrywały spotkanie. O ile wszystkie te zmienne bardzo mocno wpływały na wyniki i poprawiały jakość modelu to należałoby zastanowić się nad słusznością ich wykorzystania lub ich ewentualną modyfikacją. Parę osób z Was zwróciło mi to uwagę a ja postanowiłem się do niej odnieść w tym wpisie.
Kurs bukmacherski -> OUT
Zacznę od tego, że postanowiłem zrezygnować z wykorzystania zmiennych WHH, WHA oraz WHD. Dlaczego? Z trzech merytorycznych powodów poniżej:
- Kurs bukmacherski jest pewną miara prawdopodobieństwa końcowego wyniku spotkania. Im mniejszy kurs tym pewniejsza wygrana danej drużyny według bukmachera. Wartości te są generowane za pomocą bardzo skomplikowanych algorytmów, które przynoszą im olbrzymie zyski. Uwzględniając te wartości w naszym modelach jesteśmy skazani na ich faworyzacje w wyborze istotnych zmiennych. Głównie dlatego, że wartości te, biorąC pod uwagę długi okres, są po prostu dobre i sprawdzają się. Nie chodzi nam przecież o to aby podążać za trendem bukmachera, raczej za tym aby tworzyć własne, nowe algorytmy.
- Wybierając kurs jako zmienną wliczoną do modelu decydujemy się również na to, iż pozostałe zmienne stają się mniej istotne a zarazem nie uwzględnione w modelu. Prowadzi to do utracenia cennej informacji dotyczącej tego co tak naprawdę determinuje wynik spotkania. No przecież nie kurs bukmacherski…jak wynikało to z wcześniejszych analiz.
- Zakładając, że tworzymy własny algorytm od zera, bez wykorzystania określonej wartości bukmacherskiego algorytmu, chcemy odseparować własne wyniki od tych zaproponowanych przez zmienne reprezentujące kurs. Najbardziej przecież cieszy nas prawidłowa prognoza spotkania dla którego wartość kursu bukmacherskiego sugerowała by inaczej. Innymi słowy, my nie powielamy algorytmów oraz błędów poprzedników, my wyznaczamy nowe trendy, modele i błędy 🙂 Nie chodzi tu o to aby konkurować z bukmacherem, ale o to, że tak naprawdę przy uwzględnieniu kursu, uwzględniamy jego predykcję wyniku spotkania, a my w konsekwencji nie mamy na to żadnego wpływu.
Sprawdzenie poprawności nowego podejścia
Poza przedstawionymi powyżej przedstawionymi przyczynami należałoby sprawdzić jak przedstawiają się ich statystyczne konsekwencji i czy tak naprawdę nasz algorytm ma szansę istnieć bez kursów bukmacherskich. Innymi słowy, przeanalizujemy co stracimy wyrzucając właśnie te zmienne. Do tego celu stworzone zostały dwa modele, jeden z uwzględnieniem wszystkich zmiennych, czyli również te z kursem bukmacherskim, oraz drugi, z którego wyrzuciliśmy te zmienne. Każdy z nich został stworzony modelem pełnym, czyli wykorzystującym wszystkie zmienne ujęte w zbiorze danych. Oba modele porównane zostały na podstawie pola pod wykresem krzywej ROC na wykresie poniżej.
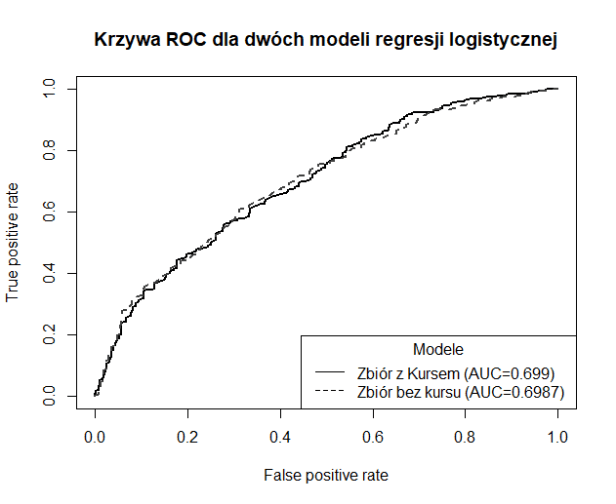
Ku zaskoczeniu, po stworzeniu modelu regresji logistycznej na zbiorze danych z usuniętymi zmiennymi dotyczącymi kursów, stwierdzamy, że jakoś modelu prawie w ogóle nie uległa zmianie. Jakość modelu zmniejszyła się wyłącznie o 0.003 jednostki, co tak naprawdę o niczym nie świadczy. Jeżeli zatem bralibyśmy pod uwagę samą jakoś dopasowania modelu do danych, to z pewnością bylibyśmy w stanie odrzucić zmienne WHH oraz WHA. Nie ujmując ich w zbiorze danych zyskujemy znacznie więcej pozbywamy się najbardziej faworyzujących zmiennych i mamy większą kontrolę nad wynikiem modelu.
Istotność zmiennych
Zwróćmy uwagę na przedstawione względne wartości istotności danej zmiennej.
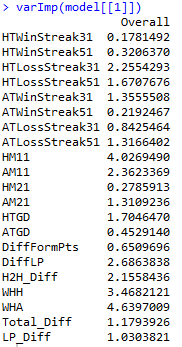
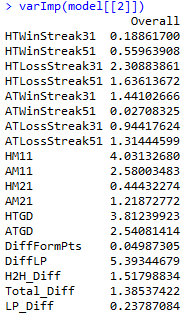
Proszę zwrócić uwagę na istotność zmiennych WHA oraz WHH w Modelu 1. Stanowią one odpowiednio pierwszą i trzecią z najistotniejszy zmienną w modelu. Innymi słowy pozostałe zmienne wnoszą stosunkowo niewiele do modelu. Tym samym, tracimy zatem informacje wnoszoną przez te zmienne. Proszę przyjrzeć się teraz względnej istotności zmiennych w modelu 2. Istotność odpowiednich zmiennych zdecydowanie wzrasta. W konsekwencji stanowią one szkielet budowanego algorytmu, a rezultaty są znacznie bardziej „czytelne” dla badacza. Mówiąc kolokwialnie, zmienne kursów bukmacherskich przytłaczają pozostałe zmienne i niwelują ich wpływ na budowę modelu.
Weryfikacja modelu po uszczupleniu liczby zmiennych
Jak zatem przekłada się to na trafność przewidywanych wyników?
Do tego celu stworzono dwie macierze trafności, a wyniki przedstawione zostały na dwóch zrzutach ekranu poniżej.


Po lewej stronie macierz trafności dla Modelu 1 czyli z uwzględnieniem zmiennych WHH oraz WHA, po prawej stronie zaś model stworzony na zbiorze danych bez tych dwóch zmiennych. Okazało się, że dokładności predykcyjne modelu są bardzo zbliżone jednak minimalnie lepszym okazał się model… bez zmiennych reprezentujących kursy bukmacherskie. Nie mamy już teraz żadnych wątpliwości co do poprawności naszego rozumowania. Doszliśmy zatem wspólnie do wniosku, że zmienne WHH oraz WHA nie poprawiają znacząco modelu oraz są zbyt bardzo faworyzowane przez model tak, że ich usunięcie wpływa pozytywnie na rezultaty predykcyjne.
Modyfikacja zmiennej Total_Diff
Poza wyrzuceniem zmiennych kursów bukmacherskich w zbiorze danych, modyfikacji została poddana inna zmienna. Mowa tu o zmiennej Total_Diff reprezentującej bezwzględną różnice wartości budżetów drużyn rozgrywających spotkanie. W zmiennej tej nie byłoby nic złego, gdybyśmy analizowali wyłącznie jeden sezon. Problem pojawia się kiedy do zbioru treningowego bierzemy obserwacje sprzed 10 lat.

Na załączonym wykresie przedstawione zostały zmiany całkowitych budżetów określonych angielskich klubów na przestrzeni ostatnich 9 lat. Na pierwszy rzut oka widać jak bardzo budżety wszystkich przedstawionych klubów wzrosły na przestrzeni ostatnich paru lat. Przy tak dynamicznym wzroście wartości zastosowanie bezwzględnych różnic tych wartości wydaje się nie uzasadnione. Przede wszystkim dlatego, że różnice między klubami 10 lat wcześniej były względnie znacznie mniejsze aniżeli np. w aktualnym sezonie. Z tego też powodu zdecydowałem się na odrzucenie bezwzględnej różnicy na rzecz zastosowania proporcji budżetów. Stosunek zdaje się bardziej odzwierciedlać rzeczywistą różnicę w budżetach klubów. Przeanalizujmy następujący przykład. W roku 2010 klub A posiadał budżet równy 4 mln, natomiast klub B – 1 mln. W ciągu 8 kolejnych lat każdy z tych klubów podwoił swój budżet, co daje nam w 2018 roku następujące budżety klub A – 8 mln, klub B- 2 mln. W 2010 różnica miedzy wartościami klubowych budżetów wynosiła 3 mln, natomiast w 2018 już 6 mln. Stosunek budżetów jednak pozostał na tym samym poziomie wynoszącym wartość 2 na rzecz klubu A. Taki zabieg jest również bardzo użyteczny przy porównywaniu wartości małych, klubów z znacznie mniejszym budżetem.
Poza przedstawioną modyfikacją zbioru danych, do jego składu wliczona została nowa oczywista zmienna LP_Diff, czyli różnica w aktualnej pozycji w tabeli między dwoma drużynami w danej kolejce.
Podsumowanie
Przedstawiłem w tym wpisie modyfikacje zbioru danych, który wykorzystujemy wspólnie do tworzenia modeli predykcyjnych wyników spotkań piłkarskich. Tak zmodyfikowany zbiór danych został już zastosowany dla wcześniej analizowanych modeli, a wyniki możecie i rezultaty możecie przeanalizować w pliku: predictions_04_11_2018.
W planach mam stworzenie oddzielnej strony, na której będziecie mogli podejrzeć aktualne tabele z najbliższymi predykcjami oraz statystykami modeli, także bądźcie czujni!
A już niedługo nowy model lasów losowych.
Wpis ten, był pierwszym wpisem w którym Wy jako odbiorcy mieliście bardzo duży wpływ sygnalizując mi swoje uwagi i spostrzeżenia. Mam nadzieję, że ta współpraca będzie się rozwijała coraz szerzej i wspólnie stworzymy coś naprawdę dobrego. Dziękuje za pomoc i do usłyszenia już niedługo w wpisie dotyczącym lasów losowych z wykorzystaniem już nowego zbioru danych!
