

Kontynuując naszą serię w której przedstawiam kolejne modele uczenia maszynowego, dziś chciałbym przedstawić algorytm lasów losowych. Forma pozostanie taka sama, więc na początku postaram się przedstawić w sposób nieskomplikowany co kryję się za terminem lasów losowych, jak działa i do czego się go stosuje. Następnie przejdę, jak zwykle już, do implementacji tego algorytmu na piłkarskich danych. Co ciekawe, w porównaniu do poprzednich modeli tym razem wykorzystamy lekko zmodyfikowany zbiór danych. Zmiany i uzasadnienie ich wprowadzenia znajdziecie tu. Sam wpis będzie 3 z koeli materiałem dotyczącym tworzenia modeli predykcyjnych. Pierwsze dwa to regresja logistyczna oraz drzewo losowe. Szczególnie ten ostatni będzie bardzo pomocny w zrozumieniu idei działania lasów losowych, jest pewnym jego rozszerzeniem i uzupełnieniem. Przy tworzeniu tego wpisu korzystałem z wielu artykułów dostępnych w internecie, jednak w szczególności zainteresowanych odsyłam pod link.
Wstęp
Zaczynając materiał dotyczący lasów losowych nie sposób nie rozpocząć do modelu drzewa decyzyjnego. Otóż lasy losowe są idealnym rozwiązaniem na problem przeuczenia często występujący modelach drzewach losowych. Jesteśmy w stanie jednak, za pomocą określonych specyficznych parametrów, niwelować przeuczenie modelu w analizowanym algorytmie. Mimo wszystko dobrym rozwiązaniem jest zastosowanie algorytmu drzew losowych, które stanowią rozszerzenie działania algorytmu drzewa decyzyjnego. Problem przeuczenia polega na zbyt dobry dopasowaniu się modelu do danych treningowych, co w konsekwencji prowadzi do słabych wyników predykcyjnych na zbiorze testowym. Dzieję się to głownie dlatego, iż model uczony jest na pewnej części zbioru danych (zbioru treningowego), który akurat nie ma zastosowania do ogółu. Innymi słowy model uczy się na tej części zbioru, która jest słabym uogólnieniem całego zbioru danych. I tu pojawia się idea wykorzystania wielu drzew decyzyjnych, które w efekcie przedstawiają uśredniony wynik wszystkich z nich.
Bagging
Lasy losowe zaliczane są do metod uczenia wykorzystywanych w problemach klasyfikacyjny i regresyjnych, które funkcjonują poprzez tworzenie wielu drzew decyzyjnych w fazie treningowej , których wynikiem są uśrednione wyniki wszystkich drzew.
Algorytm ten wykorzystuje metodę tzw. bagging’u, która redukuje różnorodność przy tworzeniu modelu. Zwróćmy uwagę, że drzewa decyzyjne w dużym stopniu zależą od zbioru na którym budowany jest model predykcyjny. Innymi słowy, wyniki predykcyjne, które otrzymamy zależą w dużej mierze od zbioru na którym był uczony model. Klasyfikacyjne oraz regresyjne drzewa decyzyjne są pod tym względem bardzo podatne na te wpływy.
Tworząc wiele modeli drzew decyzyjnych pomijamy wpływ przeuczenia pojedynczego zbiory treningowego konkretnego drzewa. W efekcie, zbudowane drzewa są względnie głębokie, czyli posiadają wiele pod-podziałów w węzłach, a dodatkowo nie zostaną przycinane. Dlatego też drzewa te mogą się miedzy sobą bardzo różnić. Dodatkowo należy podkreślić, że przy wykorzystaniu lasów losowych, nie musimy już określać tak specyficznych parametrów algorytmu, jak to było przy pojedynczym drzewie decyzyjnym. W tym przypadku potrzebujemy określenia tylko i wyłącznie ilości drzew jaka ma tworzyć cały nasz las 🙂 .Przy dużej liczbie tworzących się drzew jesteśmy narażeni na wydłużony czas przetwarzania, jednak pozbywamy się tym samym problemu przeuczenia modelu.
Od drzewa do lasu
Główną różnicą miedzy założeniami towarzyszącymi budowie algorytmu drzewa precyzyjnego oraz lasów losowych jest odmienne podejście do podziału na kolejne podzbiory w węźle. Przy budowie drzewa decyzyjnego algorytm przeszukuje całą przestrzeń, czyli wszystkie zmienne i ich wartości w celu wybrania najbardziej odpowiedniego podziału, a więc konkretnej wartości odpowiedniej zmiennej. W przypadku lasów losowych algorytm jest ograniczony tylko i wyłącznie do pewnej losowej części tej przestrzeni w której przeszukuje najlepszego rozwiązania. Lasy losowe, chociaż wpływają na utrudnioną interpretacje wyników to znaczne bardziej poprawiają jakość końcowego modelu.
Działanie algorytmu
Działanie algorytmu na podstawie artykułu.
- Losowy wybór zbioru: Każde kolejne drzewo jest uczone na mniej więcej 2/3 całego zbioru treningowego. Obserwacje wybierane są w procesie losowania ze zwracaniem z podstawowego zbioru danych. Tak wybrany zestaw obserwacji będzie stanowił zbiór treningowy na którym będzie uczone dane drzewo.
- Losowy wybór zmiennej: Dokonywany zostaje losowy wybór zmiennej objaśnianej i na jej podstawie dokonywany został podział w danym węźle.
- Dla każdego drzewa, na pozostałym zbiorze, który stanowi zbiór testowy, oszacowywana jest wartość błędnej klasyfikacji.
- Każde ze stworzonych drzew przekazuje swoje wartości predykcyjne i stanowi wkład do końcowej wartości klasyfikacyjnej. W przypadku zmiennej binarnej, każe drzewo określa wartość predykcyjną danej obserwacji. Następnie procent danej odpowiedzi stanowi wartość przewidywanego prawdopodobieństwa
Tak więc w uproszczeniu wygląda schemat działania lasów losowych. Mam zatem nasieję, że wiemy już na czym fundamentalnie polega ten algorytm dlatego w tym momencie przejdziemy do implementacji na aktualnych, piłkarskich danych.
Implementacja
Zaczynamy od przedstawienia danych. Tym razem wzięliśmy na magiel dane dotyczące włoskiej Seria A. Ostatnich 6 obserwacji przedstawia się następująco:
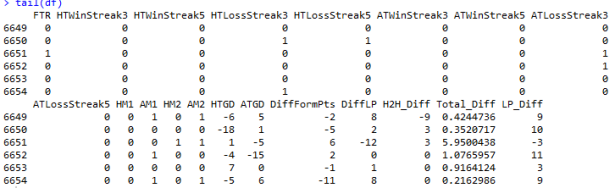
I na takim zbiorze danych, złożony, z 6654 obserwacji implementujemy algorytm lasów losowych.
rf <-randomForest(FTR~.,data=df, ntree=1500)
Przy budowie lasów jedynym paramtrem , który potrzebujemy określić jest ilość drzew decyzyjnych tworzących las losowy (ntree). W efekcie tak skonstruowanego polecenia stworzony zostanie model lasu losowego rf. Wynik działania tego algorytmu przedstawiony został na zrzucie z ekranu poniżej.
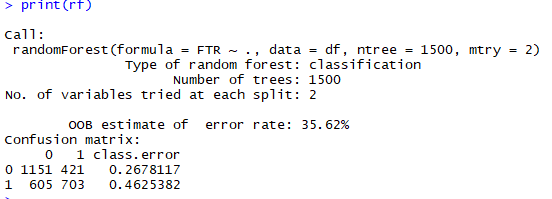
Liczba sprawdzanych zmiennych (predyktorów) przy każdym podziale wynosi 4. Wartość ta jest określona jako mtry a obliczana jest ze wzoru: pierwiastek z liczby kolumn pomniejszoną o 1. Inaczej, jest to pierwiastek z liczby zmiennych objaśniających. Parametr ten pozwoli nam na wybranie optymalnej liczby generowanych drzew decyzyjnych. W tym celu wykorzystujemy funkcje tuneRF() z pakietu randomForest w R. Budujemy 10 różnych klasyfikatorów na podstawie lasów losowych w poszukiwaniu optymalnej wartości praametru mtry przy budowie lasów losowych. Optymalna liczba czyli taka przy której procentowa wartość błędnego sklasyfikowania wyniesie minimum.
mtry <- tuneRF(df[-1],df$FTR, ntreeTry=1500,
stepFactor=1.5,improve=0.01, trace=TRUE, plot=TRUE)
W funckji tuneRF musimy określić przynajmneij dwa parametry: stepFactor oraz improve. Pierwszy wpływa na kolejne wartości paraemtry mtry, które chcemy sprawdzić, natomiast improve odnosi się do wartości poprawy wartości błędu błędnej klasyfikacji (spadku błędu) aby funkcja dalej sprawdzała koeljną wartośc parametru mtry. W efekcie otrzymujemy taki oto output:

Widzimy jak algorytm iteruje po kolejnych wartośćiach parametru mtry, zaczynając od wartości domyślnej , w nasyzm przypadku 4. Dla każdego z tych parametrów oszacowywana zostaje wartość procentowego udzuaiłu błędnie skalsyfikowanej zmiennej celu (OBB error). Okazuje się, że dla mtry=3 wartość błędu jest najmniejsza i wynosi 35.03%. Jeżeli cofniemy się do pierwszego outputu lasu lsoowego rf zauważymy (rys. 2), że wartość błędu OBB jest tam większa niż w przypadku zmiany parametru mtry na 3, co zresztą przedstawione zostaje na rysunku nr. 4.

Mając już określone wartości potrzebnych do stworzenia optymalnego modelu lasu losowego finalna postać funckji randomForest przedstawia się następująco :
rf <-randomForest(FTR~.,data=df, mtry=3, importance=TRUE,ntree=1500)
Podsumowanie funckji załączono na rysunku 5.
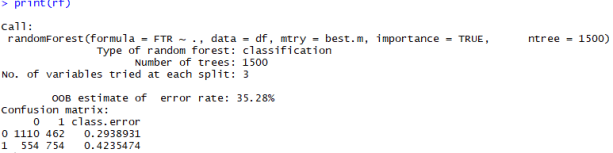
Finalny model wykazuje nieznaczną poprawę błędu klasyfikacyjnego OOB, który wynosi 35,28%. Wartość ta jest obliczana na podstawie macierzy trafności załączonej poniżej prezentacji błędu OOB. Model źle sklasyfikował aż 554 obserwacje jako „0”, chociaż w rzeczywistości wartość zmiennej celu dla tych obserwacji wynosiła „1”. Ponadto, 462 obserwacje sklasyfikowane jako „1” a w rzeczywistości były „0” Proszę zwrócić uwagę, że algorytm znacznie lepiej sklasyfikuje obserwacje, których zmienna celu wynosi „0” (spotkanie zakończone remisem lub zwycięstwem gości) aniżeli „1” (wygrana gospodarza). Przy klasyfikacji „0” algorytm pomylił się tylko w niecałych 30% , podczas gdy przy klasyfikacji „1” błąd wynosił aż 42%.
Istotność zmiennych i jakość modelu
Dla każde drzewa, które składa się na las losowy, wyliczana jest liczba poprawnych klasyfikacji zmiennej celu. Zmienne objaśniające wykorzystane przy tworzeniu każdego drzewa są wybierane losowo. W rezultacie każda kolejna zmienna w drzewie dzieli zbiór na pewne podrozdziały, w zakresie których liczony jest błąd błędnej klasyfikacji. Wykorzystując proste odejmowanie wartości błędu OOB dla danego drzewa złożonego z wylosowanych zmiennych od błędu OOB na niezmodyfikowanym zbiorze danym, jesteśmy w stanie określić wpływ danej zmiennej na jakość modelu. Innymi słowy, określamy o ile spadnie dokładność modelu, jeżeli usuniemy daną zmienną. Wynik istotności zmiennych przedstawiony został na rysunku 6.

Innym sposobem pomiaru istotności zmiennych jest Index Giniego. Za każdym razem, kiedy dokonywany jest podział na podstawie pewnej zmiennej, określana jest wartość jednorodności (wskaźnik Giniego) w wynikowych podzbiorach. W efekcie dla każdej zmiennej jesteśmy określić jej istotność na podstawie wskaźnika Giniego, który otrzymujemy wykorzystując do podziału zbioru właśnie tę zmienną. Spadek dokładności wskaźnika jednorodności przedstawiony został na wykresie 7.

Mówiąc wprost, im większa wartość na obu wykresach, tym większa jest istotność danej zmiennej w modelu. Interpretacja wyników jest dosyć intuicyjna. W obu statystykach najbardziej istotną zmienną okazała się zmienna reprezentująca różnice budżetów klubów piłkarskich, które rozgrywają spotkanie. Druga w kolejności, również w obu przypadkach, okazała się zmienna DiffLP oznaczająca bezwzględną aktualną różnicę w tabeli. Zmienne, które należałoby wyróżnić poza wspomnianymi to na pewno:
- zmienna reprezentującą różnicę sumy punktów zdobytą w ostatnich meczach przez każda z drużyn (DiffFormPts),
- różnica strzelonych i straconych bramek przez każdą z drużyn (HTGD oraz ATGD),
- ilość punktów zdobyta przeciwko danej drużynie dla każdej z nich (H2H_Diff),
- oraz różnica pozycji w tabeli na zakończenie ostatniego sezonu (LP_Diff).
Co ciekawe, żadna ze zmiennych dotyczących wyników ostatnich spotkań drużyny nie okazała się znacząco istotna.
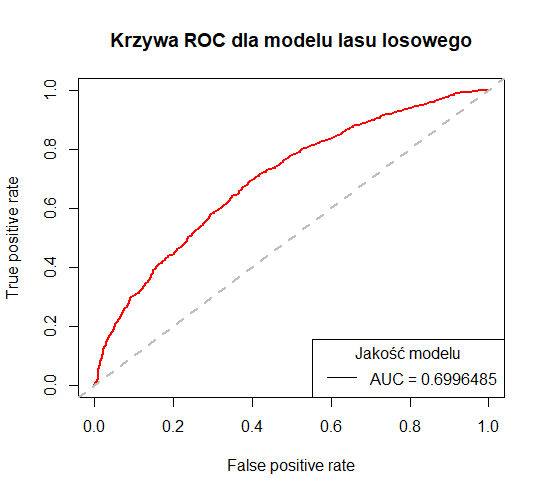
Na koniec, na rysunku nr 8 zaprezentowana została krzywa ROC dla stworzonego modelu lasu losowego. Jej dokładność mierzona polem pod wykresem tej krzywej wynosi prawie 0.70 (70%).
Dodatkowo, korzystając z okazji zachęcam do sprawdzenia dotychczasowych rezultatów poprawności naszych stworzonych modeli w załączonym pliku : predictions.
Wszystkich chętnych otrzymaniem takiego pliku z predykcjami na najbliższą kolejkę zachęcam do kontaktu. Poza załączonymi już tam modelami drzewa decyzyjnego oraz regresji logistycznej, pojawi się nowo stworzony model lasu losowego. Plik prawdopodobnie będzie gotowy tuż przed najbliższą sobotą.
Aktualizacja 2018-11-24
Z racji zbliżającej się piłkarskiej kolejki w Europie zachęcam do sprawdzenia nowych predykcji w pliku: predictions_24_11_2018
Zachęcam również do komentowania i dzielenia się z innymi! 🙂
Pozdrawiam serdecznie i życzę udanego weekendu!
